 |
 Splat-Based Metal Artifact Reduction in Cone-Beam CT via Compact Attenuation Modeling Splat-Based Metal Artifact Reduction in Cone-Beam CT via Compact Attenuation Modeling
Kiseok Choi, Jaemin Cho, Inchul Kim, Min H. Kim
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR) 2026
Denver, Colorado, United States, Jun. 3--7, 2026
|
[PDF][Supp][BibTeX] |
| |
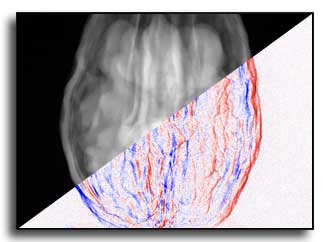
X-ray computed tomography (CT) suffers from severe metal artifacts when high-attenuation objects such as dental fillings or orthopedic implants are present. These artifacts originate from the polychromatic nature of X-rays, where attenuation varies strongly with photon energy and material composition, breaking the monochromatic assumption used by conventional reconstruction algorithms. Recent neural rendering approaches attempt to address this mismatch through differentiable polychromatic projection models, but they still struggle with smoothness bias, loss of fine structures, and prohibitive computation when extended to large-scale cone-beam CT. We introduce a splat-based metal artifact reduction framework that incorporates a physically grounded polychromatic forward model into a continuous Gaussian representation for cone-beam CT. Each Gaussian encodes the energy-dependent attenuation of the underlying material using a compact material parameterization, which enables efficient joint optimization of geometric and material properties without relying on a metal mask. This compact attenuation formulation captures the essential variation across biological tissues and metallic implants, allowing our model to explain metal-induced nonlinearity while preserving high-frequency structure. Experiments on simulated and real cone-beam CT scans show that our method converges significantly faster and suppresses metal artifacts more effectively than existing reconstruction and neural field-based approaches.
|
 |
 |
Revisiting Pose Sensitivity in Splat-based Computed Tomography under Sparse-view Reconstruction
Kiseok Choi, Hyeongjun Cho, Inchul Kim, Min H. Kim
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR) 2026
Denver, Colorado, United States, Jun. 3--7, 2026
|
[PDF][Supp][BibTeX] |
| |
X-ray computed tomography (CT) reconstructs volumetric representations of objects from projection images obtained by transmitting X-rays through a target. Recent splat-based tomography, which represents a volume as a continuous distribution of 3D Gaussians, has demonstrated both high reconstruction quality and fast convergence in cone-beam sparse-view CT. However, when deployed in real CT systems with limited and non-uniform view distributions, we observe distinctive streak and strip artifacts that are far more pronounced than in conventional reconstruction methods. Through detailed analysis, we show that these artifacts primarily originate from pose inaccuracies in the acquisition geometry rather than from view sparsity itself. We revisit pose sensitivity in the splatting formulation and derive a stable gradient-based framework that jointly refines geometric parameters during reconstruction. Our study not only identifies how pose perturbations propagate through the differentiable projection operator but also reveals why splat-based CT is particularly vulnerable to geometric misalignment. The resulting formulation remains lightweight and easily integrable into existing pipelines while substantially improving reconstruction fidelity under real-world sparse-view conditions.
|
|
 |
Dense Metric Depth Completion from Sparse Direct Time-of-Flight Sensors
Hakyeong Kim, Ruicheng Wang, Chengtang Yao, Jiaolong Yang, Min H. Kim
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR) 2026
Denver, Colorado, United States, Jun. 3--7, 2026
|
[PDF][Supp][BibTeX] |
| |
Direct Time-of-Flight (dToF) sensors provide highly accurate metric depth and are more robust than indirect ToF systems in challenging real-world conditions. However, their high manufacturing cost and limited photodiode array size produce depth maps that are extremely sparse, low-resolution, and noisy, making them unsuitable for VR/XR, robotics, and 3D perception tasks that require dense metric depth. Existing monocular and depth completion methods struggle to handle the unique sampling patterns and hardware artifacts of dToF devices, and their performance often deteriorates significantly under severe sparsity or noise. We present a generalizable framework for dense metric depth completion from sparse dToF measurements, capable of operating across diverse sensor types, sparsity levels, and noise conditions. Our model employs a depth-guided dual-branch Vision Transformer encoder that processes RGB images and sparse dToF measurements separately, while a masked joint attention module allows depth tokens to reliably guide image features without being overwritten by them. A lightweight decoder reconstructs dense metric depth efficiently, without diffusion-based or refinement-heavy post-processing. To address the scarcity of paired training data, we introduce a comprehensive dToF simulation pipeline that reproduces the characteristics of flash, sub-VGA flash, and rotating sensors, including hardware-induced degradation, irregular sparsity, and realistic noise distributions. Trained entirely on synthetic data, our model achieves strong zero-shot generalization across 6 datasets and 2 real dToF devices, outperforming state-of-the-art approaches in both accuracy and computational efficiency. This establishes a robust and practical solution for dense metric depth completion from sparse direct ToF sensors.
|
|
 |
Joint Static Calibration for Multiview Phase-Measuring Profilometry
Hyeongjun Cho, Min H. Kim
Springer Nature Computer Science 2026,
7(6), published on June 18, 2026
|
[PDF][BibTeX] |
| |
Conventional phase-measuring profilometry (PMP) calibration methods are primarily designed for single-view systems.
Extending PMP to multiview configurations typically requires separate geometric calibrations for each camera and projector,
often relying on repeated manual repositioning of a calibration target. This decoupled, two-stage procedure is
labor-intensive and prone to error accumulation and local minima. We propose a unified framework for static calibration
of multiview PMP systems that jointly optimizes geometric and phase-to-height parameters in a single formulation. Our
approach is built on two key components: (a) a compact multi-planar calibration target with embedded fiducial markers,
which removes the need for target motion, and (b) a joint optimization strategy that simultaneously estimates intrinsic,
extrinsic, and lens distortion parameters of all cameras and projectors from a single static scene. The proposed pipeline
automatically detects planar features, constructs multiview homographies via a target-aware bundle adjustment, and incorporates
unwrapped phase measurements to refine system parameters. This fully automated approach significantly reduces
user intervention while improving stability across views. Experimental results demonstrate that our method provides
accurate calibration and supports consistent fusion of multiview phase measurements.
|
|
 |
Biologically inspired microlens array camera for high-resolution wide field-of-view imaging
Jae-Myeong Kwon, Yejoon Kwon, Young-Gil Cha, Dong Hyun Han, Hyun-Kyung Kim, Je-Kyun Park, Min H. Kim, Ki-Hun Jeong
Nature Communications 2026
Mar. 23, 2026
|
[PDF][Supp][BibTeX] |
| |
Natural vision employs diverse strategies to achieve wide field-of-view imaging critical for environmental awareness. Here we report spatially offset ellipsoidal microlens array camera, inspired by the angular sampling strategy of Xenos peckii for high-resolution wide field-of-view imaging. The camera features optical units with spatially offset-coupled apertures and ellipsoidal microlenses onto a single planar sensor within a 0.94 mm total track length. Direction-specific spatial offsets and asymmetric microlens curvatures substantially reduce aberrations across a 140° field-of-view. Digital calibration and image stitching reconstruct complex surfaces such as microfluidic channels, dental phantoms, and human faces, producing one-megapixel images with 1.1-pixel error. This ultrathin camera provides high-resolution and wide field-of-view imaging of real-world targets in confined spaces for applications in machine vision, mobile imaging, and healthcare monitoring.
|
|
 |
Splat-based Metal Artifact Reduction in Cone-Beam CT via Polychromatic Modeling
Kiseok Choi, Inchul Kim, Jaemin Cho, Hyeongjun Cho, Min H. Kim
Computer Graphics Forum (CGF), presented at Eurographics 2026
Best Paper Award at Eurographics 2026
Aachen, Germany, May. 4--8, 2026
|
[PDF][Supp][code]
[dataset][BibTeX] |
| |
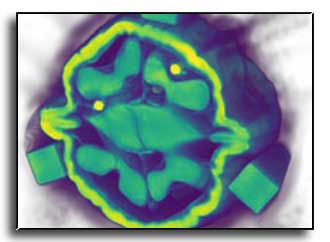
Cone-beam computed tomography (CBCT) enables volumetric reconstruction from X-ray projections, but suffers from severe artifacts--especially beam hardening--when imaging materials with high attenuation such as metals. These artifacts arise from the polychromatic nature of X-rays and are not properly addressed by conventional monochromatic reconstruction algorithms. While recent neural representation-based methods offer improved reconstruction quality, they are computationally expensive and often impractical for deployment. We propose a novel physics-inspired, self-calibrating metal artifact reduction method that efficiently reconstructs 3D CBCT volumes while correcting beam hardening artifacts. Our method integrates a polychromatic X-ray projection model, material-dependent attenuation profiles, and system response modeling into a Gaussian Splatting framework. Unlike prior work, we eliminate the need for manual metal masks or strong prior assumptions, and we optimize both reconstruction parameters and X-ray spectral characteristics jointly during training. We further introduce a high-fidelity synthetic CBCT dataset generation pipeline validated on Monte-Carlo x-ray simulation toolbox and release new datasets with severe metal-induced artifacts to support the community. This is the first splat-based method for reducing beam hardening in CBCT. Extensive experiments on both synthetic and real-world datasets demonstrate that our method outperforms state-of-the-art approaches in artifact suppression and reconstruction accuracy.
|
|
 |
Splat-based Gradient-domain Fusion for Seamless View Transition
Dongyoung Choi, Jaemin Cho, Woohyun Kang, Hyunho Ha, James Tompkin, Min H. Kim
Proc. Int. Conf. 3D Vision (3DV) 2026,
Vancouver, BC, Canada, Mar. 20--23, 2026
|
[PDF][Supp][BibTeX] |
| |
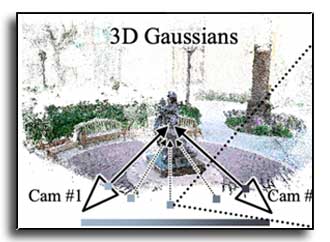
In sparse novel view synthesis with few input views and wide baselines, existing methods often fail due to weak geometric correspondences and view-dependent color inconsistencies. Splatting-based approaches can produce plausible results near training views, but they frequently overfit and struggle to maintain smooth, realistic appearance transitions in novel viewpoints. We introduce a splat-based gradient-domain fusion method that addresses these limitations. Our approach first establishes reliable dense geometry via two-view stereo for stable initialization. We then generate intermediate virtual views by reprojecting input images, which provide reference gradient fields for gradient-domain fusion. By blending these gradients, our method transfers low-frequency, view-dependent colors to the rendered Gaussians, producing seamless appearance transitions across views. Extensive experiments show that our approach consistently outperforms state-of-the-art sparse Gaussian splatting methods, delivering robust and perceptually plausible view synthesis. A comprehensive user study further confirms that our results are perceptually preferred, with significantly smoother and more realistic color transitions than existing methods.
|
|
 |
Consistent Multi-Lane Tracking with Temporally Recursive Spline Modeling
Sanghyeon Lee, Donghun Kang, Min H. Kim
Proc. Int. Conf. Computer Vision, Theory and Applications (VISAPP) 2026,
Marbella, Spain, Mar. 9 -- 11, 2026
|
[PDF][BibTeX] |
| |
Lane recognition and tracking are essential for autonomous driving, providing precise positioning and navigation data for vehicles. Existing single-image lane detection methods often falter in real-world conditions like poor lighting and occlusions. Video-based approaches, while leveraging sequential frames, typically lack continuity in lane tracking, leading to fragmented lane representations. We introduce a novel approach that addresses these challenges through temporally recursive spline modeling, a robust framework designed to maintain consistent, multi-lane tracking over time. Unlike traditional methods that limit tracking to adjacent lanes, our technique models lane trajectories as temporally recursive splines mapped in world space, capturing smooth lane continuity and enhancing long-term tracking fidelity across complex driving scenes. Our framework incorporates 2D image-based lane detections into a recursive spline model, facilitating accurate, real-time lane trajectory representation across frames. To ensure reliable lane association and continuity, we integrate a Kalman filter and an adaptive Hungarian algorithm, allowing our method to enhance baseline detectors and support consistent multi-lane tracking. Experimental results demonstrate that our temporally recursive spline modeling outperforms conventional approaches in lane detection and tracking metrics, achieving superior continuous lane recognition in challenging driving environments.
|
|
 |
Diffusion-Based HDR Reconstruction from Mosaiced Exposure Images
Seeha Lee, Dongyoung Choi, Min H. Kim
Proc. Int. Conf. Computer Vision, Theory and Applications (VISAPP) 2026,
Marbella, Spain, Mar. 9 -- 11, 2026
|
[PDF][BibTeX] |
| |
Snapshot-based HDR imaging from Bayer-patterned multi-exposure inputs has gained significant attention with recent advancements in HDR imaging technology. Learning-based approaches have enabled the reconstruction of HDR images from extremely sparse multi-exposure measurements captured on a single Bayer-patterned sensor. However, existing learning-based methods predominantly rely on tone-mapped representations due to the inherent challenges of direct supervision in the HDR radiance domain. This tone-mapping-based approach suffers from critical limitations, including amplified noise and structural distortions in the reconstructed HDR images. The fundamental challenge arises from the high dynamic range of HDR radiance values, which exhibit a sparse and uneven distribution in floating-point space, making gradient-based optimization unstable. To address these issues, we propose a novel diffusion-based HDR reconstruction framework that operates directly in a split HDR radiance domain while preserving the linearity of the original HDR radiance values. By leveraging the generative power of diffusion models, our approach effectively learns the structural and radiometric characteristics of HDR images, leading to superior detail preservation, reduced noise artifacts, and enhanced reconstruction fidelity. Experiments demonstrate that our method outperforms state-of-the-art techniques in both qualitative and quantitative evaluations.
|
|
 |
Designing and Fabricating Color BRDFs with Differentiable Wave Optics
Yixin Zeng, Kiseok Choi, Hadi Amata, Kaizhang Kang, Wolfgang Heidrich, Hongzhi Wu,
Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2025,
44(6), Dec. 15 – 18. 2025
|
[PDF][Supple][code]
[BibTeX] |
| |
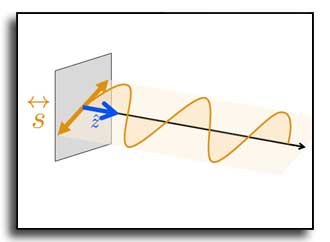
Modeling surface reflectance is central to connecting optical theory with real-world rendering and fabrication. While analytic BRDFs remain standard in rendering, recent advances in geometric and wave optics have expanded the design space for complex reflectance effects. However, existing wave-optics-based methods are limited to controlling reflectance intensity only, lacking the ability to design full-spectrum, color-dependent BRDFs. In this work, we present the first method for designing and fabricating color BRDFs using a fully differentiable wave optics framework. Our differentiable and memory-efficient simulation framework supports end-to-end optimization of microstructured surfaces under scalar diffraction theory, enabling joint control over both angular intensity and spectral color of reflectance. We leverage grayscale lithography with a feature size of 1.5--2.0\,$\mu$m to fabricate 15 BRDFs spanning four representative categories: anti-mirrors, pictorial reflections, structural colors, and iridescences. Compared to prior work, our approach achieves significantly higher fidelity and broader design flexibility, producing physically accurate and visually compelling results. By providing a practical and extensible solution for full-color BRDF design and fabrication, our method opens up new opportunities in structural coloration, product design, security printing, and advanced manufacturing.
|
|
 |
Frame-Free Representation of Polarized Light for Resolving Stokes Vector Singularities
Shinyoung Yi, Jiwoong Na, Seungmin Hwang, Inseung Hwang, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2025,
44(6), Dec. 15 – 18. 2025
|
[PDF][Supple][code]
[BibTeX] |
| |
Stokes parameters are the standard representation of polarized light intensity in Mueller calculus and are widely used in polarization-aware computer graphics. However, their reliance on local frames--aligned with ray propagation directions--introduces a fundamental limitation: numerical discontinuities in Stokes vectors despite physically continuous fields of polarized light. This issue originates from the Hairy Ball Theorem, which guarantees unavoidable singularities in any frame-dependent function defined over spherical directional domains. In this paper, we overcome this long-standing challenge by introducing the first frame-free representation of Stokes vectors. Our key idea is to reinterpret a Stokes vector as a Dirac delta function over the directional domain and project it onto spin-2 spherical harmonics, retaining only the lowest-frequency coefficients. This compact representation supports coordinate-invariant interpolation and distance computation between Stokes vectors across varying ray directions--without relying on local frames. We demonstrate the advantages of our approach in two representative applications: spherical resampling of polarized environment maps (e.g., between cube map and equirectangular formats), and view synthesis from polarized radiance fields. In both cases, conventional frame-dependent methods produce singularity artifacts. In contrast, our frame-free representation eliminates these artifacts, improves numerical robustness, and simplifies implementation by decoupling polarization encoding from local frames.
|
|
 |
Hyperspectral Polarimetric BRDFs of Real-world Materials
Yunseong Moon, Ryota Maeda, Suhyun Shin, Inseung Hwang, Youngchan Kim, Min H. Kim, Seung-Hwan Baek
Proc. ACM SIGGRAPH Asia 2025,
Hong Kong, China, Dec. 15 – 18. 2025
|
[PDF][Data][code]
[BibTeX] |
| |
Acquiring bidirectional reflectance distribution functions (BRDFs) is essential for simulating light transport and analytically modeling material properties. Over the past two decades, numerous intensity-only BRDF datasets in the visible spectrum have been introduced, primarily for RGB image rendering applications. However, in scientific and engineering domains, there remains an unmet need to model light transport with polarization a fundamental wave property of light across hyperspectral bands. To address this gap, we present the first hyperspectral-polarimetric BRDF (hpBRDF) dataset, spanning wavelengths from 414 to 950 nm and densely sampled at 68 spectral bands. This dataset covers both the visible and near-infrared (NIR) spectra, enabling detailed material analysis and light reflection simulations that incorporate polarization at each narrow spectral band. We develop an efficient hpBRDF acquisition system that captures high-dimensional hpBRDFs within a practical acquisition time. Using this system, we analyze the hpBRDFs with respect to their dependencies on wavelength, polarization state, material type, and illumination/viewing geometry. We further perform numerical analyses, including principal component analysis (PCA) and the development of a neural hpBRDF representation for continuous modeling.
|
|
 |
Splat-based 3D Scene Reconstruction with Extreme Motion-blur
Hyeonjoong Jang, Dongyoung Choi, Donggun Kim, Woohyun Kang, Min H. Kim
Proc. IEEE/CVF International Conference on Computer Vision (ICCV) 2025
Honolulu, HI, United States, Oct. 19 – 23, 2025
|
[PDF][Supple][BibTeX] |
| |
We propose a splat-based 3D scene reconstruction method from RGB-D input that effectively handles extreme motion blur, a frequent challenge in low-light environments. Under dim illumination, RGB frames often suffer from severe motion blur due to extended exposure times, causing traditional camera pose estimation methods, such as COLMAP, to fail. This results in inaccurate camera pose and blurry color input, compromising the quality of 3D reconstructions. Although recent 3D reconstruction techniques like Neural Radiance Fields and Gaussian Splatting have demonstrated impressive results, they rely on accurate camera trajectory estimation, which becomes challenging under fast motion or poor lighting conditions. Furthermore, rapid camera movement and the limited field of view of depth sensors reduce point cloud overlap, limiting the effectiveness of pose estimation with the ICP algorithm. To address these issues, we introduce a method that combines camera pose estimation and image deblurring using a Gaussian Splatting framework, leveraging both 3D Gaussian splats and depth inputs for enhanced scene representation. Our method first aligns consecutive RGB-D frames through optical flow and ICP, then refines camera poses and 3D geometry by adjusting Gaussian positions for optimal depth alignment. To handle motion blur, we model camera movement during exposure and deblur images by comparing the input with a series of sharp, rendered frames. Experiments on a new RGB-D dataset with extreme motion blur show that our method outperforms existing approaches, enabling high-quality reconstructions even in challenging conditions. This approach has broad implications for 3D mapping applications in robotics, autonomous navigation, and augmented reality. Both code and dataset will be publicly available.
|
|
 |
Benchmarking Burst Super-Resolution for Polarization Images: Noise Dataset and Analysis
Inseung Hwang, Kiseok Choi, Hyunho Ha, Min H. Kim
Proc. IEEE/CVF International Conference on Computer Vision (ICCV) 2025
Honolulu, HI, United States, Oct. 19 – 23, 2025
|
[PDF][Code][Supple]
[BibTeX] |
| |
Snapshot polarization imaging calculates polarization states from linearly polarized subimages. To achieve this, a polarization camera employs a double Bayer-patterned sensor to capture both color and polarization. It demonstrates low light efficiency and low spatial resolution, resulting in increased noise and compromised polarization measurements. Although burst super-resolution effectively reduces noise and enhances spatial resolution, applying it to polarization imaging poses challenges due to the lack of tailored datasets and reliable ground truth noise statistics. To address these issues, we introduce PolarNS and PolarBurstSR, two innovative datasets developed specifically for polarization imaging. PolarNS provides characterization of polarization noise statistics, facilitating thorough analysis, while PolarBurstSR functions as a benchmark for burst super-resolution in polarization images. These datasets, collected under various real-world conditions, enable comprehensive evaluation. Additionally, we present a model for analyzing polarization noise to quantify noise propagation, tested on a large dataset captured in a darkroom environment. As part of our application, we compare the latest burst super-resolution models, highlighting the advantages of training tailored to polarization compared to RGB-based methods. This work establishes a benchmark for polarization burst super-resolution and offers critical insights into noise propagation, thereby enhancing polarization image reconstruction.
|
|
 |
Geometry-guided Online 3D Video Synthesis with Multi-View Temporal Consistency
Hyunho Ha, Lei Xiao, Christian Richardt, Thu Nguyen-Phuoc, Changil Kim, Min H. Kim, Douglas Lanman, Numair Khan
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR) 2025
Nashville, TN, United States, Jun. 11--15, 2025
|
[PDF][BibTeX] |
| |
We introduce a novel geometry-guided online video view synthesis method with enhanced view and temporal consistency. Traditional approaches achieve high-quality synthesis from dense multi-view camera setups but require significant computational resources. In contrast, selective-input methods reduce this cost but often compromise quality, leading to multi-view and temporal inconsistencies such as flickering artifacts. Our method addresses this challenge to deliver efficient, high-quality novel-view synthesis with view and temporal consistency. The key innovation of our approach lies in using global geometry to guide an image-based rendering pipeline. To accomplish this, we progressively refine depth maps using color difference masks across time. These depth maps are then accumulated through truncated signed distance fields (TSDF) in the synthesized view's image space. This depth representation is view and temporally consistent, and is used to guide a pre-trained blending network that fuses multiple forward-rendered input-view images. Thus, the network is encouraged to output geometrically consistent synthesis results across multiple views and time. Our approach achieves consistent, high-quality video synthesis, while running efficiently in an online manner.
|
|
 |
Biologically-inspired Microlens Array Camera for High-speed and High-sensitivity Imaging
Hyun-Kyung Kim, Young-Gil Cha, Jae-Myeong Kwon, Sang-In Bae, Kisoo Kim, Kyung-Won Jang, Yong-Jin Jo, Min H. Kim, Ki-Hun Jeong
AAAS Science Advances,
Jan. 1, 2025
|
[PDF][BibTeX] |
| |
Nocturnal and crepuscular fast-eyed insects often exploit multiple optical channels and temporal summation for fast and low-light imaging. Here we report high-speed and high-sensitive microlens array camera (HS-MAC), inspired by multiple optical channels and temporal summation for insect vision. HS-MAC features crosstalk-free offset microlens arrays on a single rolling shutter CMOS image sensor and performs high-speed and high-sensitivity imaging by employing channel fragmentation, temporal summation, and compressive frame reconstruction. The experimental results demonstrate that HS-MAC accurately measures the speed of a color disk rotating at 1,950 rpm, recording fast sequences at 9,120 fps with low noise equivalent irradiance (0.43 µW/cm²). Besides, HS-MAC visualizes the necking pinch-off of a pool fire flame in dim light conditions below one-thousandth of a lux. The compact high-speed low-light camera can offer a distinct route for high-speed and low-light imaging in mobile, surveillance, and biomedical applications.
|
|
 |
Editing Scene Illumination and Material Appearance
of Light-Field Images
Jaemin Cho, Dongyoung Choi, Dahyun Kang, Gun Bang, Min H. Kim
Proc. International Conference on Computer Vision Theory and Applications (VISAPP 2025),
Porto, Portugal, Feb. 26--28, 2025
|
[PDF][BibTeX] |
| |
In this paper, we propose a method for editing the scene appearance of light-field images. Our method enables
users to manipulate the illumination and material properties of scenes captured in light-field format, offering
various control over image appearance, including dynamic relighting and material appearance modification,
which leverages our specially designed inverse rendering framework for light-field images. By effectively
separating light fields into appearance parameters—such as diffuse albedo, normal, specular intensity, and
roughness within a multi-plane image domain, we overcome the traditional challenges of light-field imaging
decomposition. These challenges include handling front-parallel views and a limited image count, which
have previously hindered neural inverse rendering networks when applying them to light-field image data.
Our method also approximates environmental illumination using spherical Gaussians, significantly enhancing
the realism of scene reflectance. Furthermore, by differentiating scene illumination into far-bound and nearbound
light environments, our method enables highly realistic editing of scene appearance and illumination,
especially for local illumination effects. This differentiation allows for efficient, real-time relighting rendering
and integrates seamlessly with existing layered light-field rendering frameworks. Our method demonstrates
rendering capabilities from casually captured light-field images.
|
|
 |
Joint Calibration of Cameras and Projectors for Multiview Phase Measuring Profilometry
Hyeongjun Cho, Min H. Kim
Proc. International Conference on Computer Vision Theory and Applications (VISAPP 2025),
Porto, Portugal, Feb. 26--28, 2025
|
[PDF][Supple][BibTeX] |
| |
Existing camera-projector calibration for phase-measuring profilometry (PMP) is valid for only a single view.
To extend a single-view PMP to a multiview system, an additional calibration, such as Zhang’s method, is necessary.
In addition to calibrating phase-to-height relationships for each view, calibrating parameters of multiple
cameras, lenses, and projectors by rotating a target is indeed cumbersome and often fails with the local optima
of calibration solutions. In this work, to make multiview PMP calibration more convenient and reliable, we
propose a joint calibration method by combining these two calibration modalities of phase-measuring profilometry
and multiview geometry with high accuracy. To this end, we devise (1) a novel compact, static
calibration target with planar surfaces of different orientations with fiducial markers and (2) a joint multiview
optimization scheme of the projectors and the cameras, handling nonlinear lens distortion. First, we automatically
detect the markers to estimate plane equation parameters of different surface orientations. We then
solve homography matrices of multiple planes through target-aware bundle adjustment. Given unwrapped
phase measurement, we calibrate intrinsic/extrinsic/lens-distortion parameters of every camera and projector
without requiring any manual interaction with the calibration target. Only one static scene is required for
calibration. Results validate that our calibration method enables us to combine multiview PMP measurements
with high accuracy.
|
|
 |
Polarimetric BSSRDF Acquisition of Dynamic Faces
Hyunho Ha, Inseung Hwang, Nestor Monzon, Jaemin Cho, Donggun Kim, Seung-Hwan Baek, Adolfo Muñoz, Diego Gutierrez, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2024,
43(6), Dec. 3 -- 6, 2024
|
[PDF][Supple][code]
[BibTeX] |
| |
Acquisition and modeling of polarized light reflection and scattering help reveal the shape, structure, and physical characteristics of an object, which is increasingly important in computer graphics.
However, current polarimetric acquisition systems are limited to static and opaque objects.
Human faces, on the other hand, present a particularly difficult challenge, given their complex structure and reflectance properties, the strong presence of spatially-varying subsurface scattering, and their dynamic nature.
We present a new polarimetric acquisition method for dynamic human faces, which focuses on capturing spatially varying appearance and precise geometry, across a wide spectrum of skin tones and facial expressions. It includes both single and heterogeneous subsurface scattering, index of refraction, and specular roughness and intensity, among other parameters, while revealing biophysically-based components such as inner- and outer-layer hemoglobin, eumelanin and pheomelanin.
Our method leverages such components' unique multispectral absorption profiles to quantify their concentrations, which in turn inform our model about the complex interactions occurring within the skin layers.
To our knowledge, our work is the first to simultaneously acquire polarimetric and spectral reflectance information alongside biophysically-based skin parameters and geometry of dynamic human faces.
Moreover, our polarimetric skin model integrates seamlessly into various rendering pipelines.
|
|
 |
Spin-Weighted Spherical Harmonics for Polarized Light Transport
Shinyoung Yi, Donggun Kim, Jiwoong Na, Xin Tong, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2024,
43(4), Jul. 28 - Aug. 1, 2024
|
[PDF][Supple][code]
[BibTeX] |
| |
The objective of polarization rendering is to simulate the interaction of light with materials exhibiting polarization-dependent behavior. However, integrating polarization into rendering is challenging and increases computational costs significantly. The primary difficulty lies in efficiently modeling and computing the complex reflection phenomena associated with polarized light. Specifically, frequency-domain analysis, essential for efficient environment lighting and storage of complex light interactions, is lacking. To efficiently simulate and reproduce polarized light interactions using frequency-domain techniques, we address the challenge of maintaining continuity in polarized light transport represented by Stokes vectors within angular domains. The conventional spherical harmonics method cannot effectively handle continuity and rotation invariance for Stokes vectors. To overcome this, we develop a new method called polarized spherical harmonics (PSH) based on the spin-weighted spherical harmonics theory. Our method provides a rotation-invariant representation of Stokes vector fields. Furthermore, we introduce frequency domain formulations of polarized rendering equations and spherical convolution based on PSH. We first define spherical convolution on Stokes vector fields in the angular domain, and it also provides efficient computation of polarized light transport, nearly on an entry-wise product in the frequency domain. Our frequency domain formulation, including spherical convolution, led to the development of the first real-time polarization rendering technique under polarized environmental illumination, named precomputed polarized radiance transfer, using our polarized spherical harmonics. Results demonstrate that our method can effectively and accurately simulate and reproduce polarized light interactions in complex reflection phenomena, including polarized environmental illumination and soft shadows.
|
|
 |
OmniLocalRF: Omnidirectional Local Radiance Fields from Dynamic Videos
Dongyoung Choi, Hyeonjoong Jang, Min H. Kim
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR 2024)
Seattle, United States, Jun. 17 – 21, 2024
|
[PDF][Supple][code]
[BibTeX] |
| |
Omnidirectional cameras are extensively used in various applications to provide a wide field of vision. However, they face a challenge in synthesizing novel views due to the inevitable presence of dynamic objects, including the photographer, in their wide field of view. In this paper, we introduce a new approach called Omnidirectional Local Radiance Fields (OmniLocalRF) that can render static-only scene views, removing and inpainting dynamic objects simultaneously. Our approach combines the principles of local radiance fields with the bidirectional optimization of omnidirectional rays. Our input is an omnidirectional video, and we evaluate the mutual observations of the entire angle between the previous and current frames. To reduce ghosting artifacts of dynamic objects and inpaint occlusions, we devise a multi-resolution motion mask prediction module. Unlike existing methods that primarily separate dynamic components through the temporal domain, our method uses multi-resolution neural feature planes for precise segmentation, which is more suitable for long 360{\degree} videos. Our experiments validate that OmniLocalRF outperforms existing methods in both qualitative and quantitative metrics, especially in scenarios with complex real-world scenes. In particular, our approach eliminates the need for manual interaction, such as drawing motion masks by hand and additional pose estimation, making it a highly effective and efficient solution.
|
|
 |
OmniSDF: Scene Reconstruction using Omnidirectional Signed Distance Functions and Adaptive Binoctrees
Hakyeong Kim, Andreas Meuleman, Hyeonjoong Jang, James Tompkin, Min H. Kim
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR 2024)
Seattle, United States, Jun. 17 – 21, 2024
|
[PDF][Supple][code]
[BibTeX] |
| |
We present a method to reconstruct indoor and outdoor static scene geometry and appearance from an omnidirectional video moving in a small circular sweep. This setting is challenging because of the small baseline and large depth ranges. These create large variance in the estimation of ray crossings, and make optimization of the surface geometry challenging. To better constrain the optimization, we estimate the geometry as a signed distance field within a spherical binoctree data structure, and use a complementary efficient tree traversal strategy based on breadth-first search for sampling. Unlike regular grids or trees, the shape of this structure well-matches the input camera setting, creating a better trade-off in the memory-quality-compute space. Further, from an initial dense depth estimate, the binoctree is adaptively subdivided throughout optimization. This is different from previous methods that may use a fixed depth, leaving the scene undersampled. In comparisons with three current methods (one neural optimization and two non-neural), our method shows decreased geometry error on average, especially in a detailed scene, while requiring orders of magnitude fewer cells than naive grids for the same minimum voxel size.
|
|
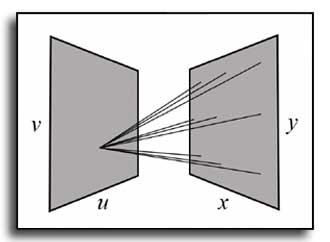 |
Are Multi-view Edges Incomplete for Depth Estimation?
Numair Khan, Min H. Kim, James Tompkin
International Journal of Computer Vision (IJCV)
Published in 2024
|
[PDF][BibTeX][project] |
| |
Depth estimation tries to obtain 3D scene geometry from low-dimensional data like 2D images. This is a vital operation in computer vision and any general solution must preserve all depth information of potential relevance to support higher-level tasks. For scenes with well-defined depth, this work shows that multi-view edges can encode all relevant information—that multi-view edges are complete. For this, we follow Elder’s complementary work on the completeness of 2D edges for image reconstruction. We deploy an image-space geometric representation: an encoding of multi-view scene edges as constraints and a diffusion reconstruction method for inverting this code into depth maps. Due to inaccurate constraints, diffusion-based methods have previously underperformed against deep learning methods; however, we will reassess the value of diffusion-based methods and show their competitiveness without requiring training data. To begin, we work with structured light fields and Epipolar Plane Images (EPIs). EPIs present high-gradient edges in the angular domain: with correct processing, EPIs provide depth constraints with accurate occlusion boundaries and view consistency. Then, we present a differentiable representation form that allows the constraints and the diffusion reconstruction to be optimized in an unsupervised way via a multi-view reconstruction loss. This is based around point splatting via radiative transport, and extends to unstructured multi-view images. We evaluate our reconstructions for accuracy, occlusion handling, view consistency, and sparsity to show that they retain the geometric information required for higher-level tasks.
|
|
 |
Self-Calibrating, Fully Differentiable NLOS Inverse Rendering
Kiseok Choi, Inchul Kim, Dongyoung Choi, Julio Marco, Diego Gutierrez, Min H. Kim
Proc. ACM SIGGRAPH Asia 2023
Sydney, NSW, Australia, December 12 -- 15, 2023
|
[PDF][Supple][Code]
[BibTeX] |
| |
Existing time-resolved non-line-of-sight (NLOS) imaging methods reconstruct hidden scenes by inverting the optical paths of indirect illumination measured at visible relay surfaces. These methods are prone to reconstruction artifacts due to inversion ambiguities and capture noise, which are typically mitigated through the manual selection of filtering functions and parameters. We introduce a fully-differentiable end-to-end NLOS inverse rendering pipeline that self-calibrates the imaging parameters during the reconstruction of hidden scenes, using as input only the measured illumination while working both in the time and frequency domains. Our pipeline extracts a geometric representation of the hidden scene from NLOS volumetric intensities and estimates the time-resolved illumination at the relay wall produced by such geometric information using differentiable transient rendering. We then use gradient descent to optimize imaging parameters by minimizing the error between our simulated time-resolved illumination and the measured illumination. Our end-to-end differentiable pipeline couples diffraction-based volumetric NLOS reconstruction with path-space light transport and a simple ray marching technique to extract detailed, dense sets of surface points and normals of hidden scenes.We demonstrate the robustness of our method to consistently reconstruct geometry and albedo, even under significant noise levels.
|
|
 |
Joint Demosaicing and Deghosting of Time-Varying Exposures
for Single-Shot HDR Imaging
Jungwoo Kim, Min H. Kim
Proc. IEEE/CVF International Conference on Computer Vision (ICCV 2023)
Paris, France, Oct. 4 -- 6, 2023
|
[PDF][Supple][Code]
[BibTeX] |
| |
The quad-Bayer patterned image sensor has made significant improvements in spatial resolution over recent years due to advancements in image sensor technology. This has enabled single-shot high-dynamic-range (HDR) imaging using spatially varying multiple exposures. Popular methods for multi-exposure array sensors involve varying the gain of each exposure, but this does not effectively change the photoelectronic energy in each exposure. Consequently, HDR images produced using gain-based exposure variation may suffer from noise and details being saturated. To address this problem, we intend to use time-varying exposures in quad-Bayer patterned sensors. This approach allows long-exposure pixels to receive more photon energy than short- or middle-exposure pixels, resulting in higher-quality HDR images. However, time-varying exposures are not ideal for dynamic scenes and require an additional deghosting method. To tackle this issue, we propose a single-shot HDR demosaicing method that takes time-varying multiple exposures as input and jointly solves both the demosaicing and deghosting problems. Our method uses a feature-extraction module to handle mosaiced multiple exposures and a multiscale transformer module to register spatial displacements of multiple exposures and colors. We also created a dataset of quad-Bayer sensor input with time-varying exposures and trained our network using this dataset. Results demonstrate that our method outperforms baseline HDR reconstruction methods with both synthetic and real datasets. With our method, we can achieve high-quality HDR images in challenging lighting conditions.
|
|
 |
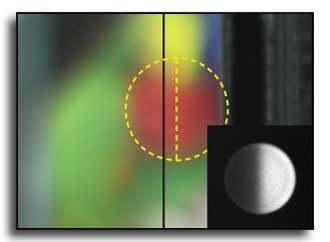
Microlens array camera with variable apertures for single-shot high dynamic range (HDR) imaging
Young-Gil Cha, Jiwoong Na, Hyun-Kyung Kim, Jae-Myeong Kwon, Seok-Haeng Huh, Seung-Un Jo, Chang-Hwan Kim, Min H. Kim, Ki-Hun Jeong
Optics Express (OE)
Vol. 31, Issue 18, pp. 29589-29595 (2023)
|
[PDF][BibTeX] |
| |
We report a microlens array camera with variable apertures (MACVA) for high dynamic range (HDR) imaging by using microlens arrays with various sizes of apertures. The MACVA comprises variable apertures, microlens arrays, gap spacers, and a CMOS image sensor. The microlenses with variable apertures capture low dynamic range (LDR) images with different f-stops under single-shot exposure. The reconstructed HDR images clearly exhibit expanded dynamic ranges surpassing LDR images as well as high resolution without motion artifacts, comparable to the maximum MTF50 value observed among the LDR images. This compact camera provides, what we believe to be, a new perspective for various machine vision or mobile devices applications.
|
 |
Spatio-Focal Bidirectional Disparity Estimation from a Dual-Pixel Image
Donggun Kim, Hyeonjoong Jang, Inchul Kim, Min H. Kim
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR 2023)
Vancouver, Canada, Jun. 18 - 22, 2023
|
[PDF][Supple][code]
[BibTeX] |
| |
Dual-pixel photography introduces a new era of monoc- ular RGB-D photography with ultra-high resolution, en- abling many applications in computational photography. However, to fully utilize dual-pixel photography, several challenges still remain. Unlike the conventional stereo pair, the dual pixel exhibits a bidirectional disparity that includes both positive and negative values, depending on the focus-plane depth in an image. Furthermore, captur- ing a wide range of dual-pixel disparity requires a shallow depth of field, resulting in a severely blurred image, degrad- ing depth estimation performance. Recently, several data- driven approaches have been proposed to mitigate these two challenges. However, due to the lack of the ground- truth dataset of the bidirectional dual-pixel disparity, ex- isting data-driven methods estimate unidirectional informa- tion only, either inverse depth or blurriness map. In this work, we propose a self-supervised learning method that learns bidirectional disparity from anisotropic blur kernels in dual-pixel photography. Our method does not rely on a training dataset of bidirectional disparity that does not ex- ist yet. Our method can estimate a complete bidirectional disparity map with respect to the focus-plane depth from a dual-pixel image, outperforming the baseline dual-pixel methods.
|
|
 |
Polarimetric iToF: Measuring High-Fidelity Depth through Scattering Media
Daniel S. Jeon, Andreas Meuleman, Seung-Hwan Baek, Min H. Kim
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR 2023)
selected as CVPR Highlights (10% of the accepted papers)
Vancouver, Canada, Jun. 18 - 22, 2023
|
[PDF][Supple][BibTeX] |
| |
Indirect time-of-flight (iToF) imaging allows us to capture dense depth information at a low cost. However, iToF imag- ing often suffers from multipath interference (MPI) arti- facts in the presence of scattering media, resulting in se- vere depth-accuracy degradation. For instance, iToF cam- eras cannot measure depth accurately through fog because ToF active illumination scatters back to the sensor before reaching the farther target surface. In this work, we pro- pose a polarimetric iToF imaging method that can capture depth information robustly through scattering media. Our observations on the principle of indirect ToF imaging and polarization of light allow us to formulate a novel computa- tional model of scattering-aware polarimetric phase mea- surements that enables us to correct MPI errors. We first devise a scattering-aware polarimetric iToF model that can estimate the phase of unpolarized backscattered light. We then combine the optical filtering of polarization and our computational modeling of unpolarized backscattered light via scattering analysis of phase and amplitude. This allows us to tackle the MPI problem by estimating the scattering energy through the participating media. We validate our method on an experimental setup using a customized off- the-shelf iToF camera. Our method outperforms baseline methods by a significant margin by means of our scattering model and polarimetric phase measurements.
|
|
 |
Progressively Optimized Local Radiance Fields for Robust View Synthesis
Andreas Meuleman, Yu-Lun Liu, Chen Gao, Jia-Bin Huang, Changil Kim, Min H. Kim, Johannes Kopf
Proc. IEEE/CVF Computer Vision and Pattern Recognition (CVPR 2023)
Vancouver, Canada, Jun. 18 - 22, 2023
|
[PDF][Supple][Code]
[BibTeX] |
| |
We present an algorithm for reconstructing the radiance field of a large-scale scene from a single casually captured video. The task poses two core challenges. First, most existing radiance field reconstruction approaches rely on accurate pre-estimated camera poses from Structurefrom-Motion algorithms, which frequently fail on in-thewild videos. Second, using a single, global radiance field with finite representational capacity does not scale to longer trajectories in an unbounded scene. For handling unknown poses, we jointly estimate the camera poses with radiance field in a progressive manner. We show that progressive optimization significantly improves the robustness of the re-construction. For handling large unbounded scenes, we dynamically allocate new local radiance fields trained with frames within a temporal window. This further improves robustness (e.g., performs well even under moderate pose drifts) and allows us to scale to large scenes. Our extensive evaluation on the TANKS AND TEMPLES dataset and our collected outdoor dataset, STATIC HIKES, show that our approach compares favorably with the state-of-the-art.
|
|
 |
Automated Visual Inspection of Defects in Transparent Display Layers using Light-Field 3D Imaging
Hyeonjoong Jang, Sanghoon Cho, Daniel S. Jeon, Dahyun Kang, Myeongho Song, Changhyun Park, Jaewon Kim, Min H. Kim
IEEE Transactions on Semiconductor Manufacturing (TSM)
Published on May 26, 2023
|
[PDF][BibTeX] |
| |
Since a display panel comprises multiple layered components, defects may occur within different layers through manufacturing processes. Traditional visual inspection systems with a 2D camera cannot identify the occurrence location among layers. Several 3D imaging technologies, such as CT, TSOM, and MRI, suffer from slow performance and a large form factor. In this work, we propose a novel visual inspection method to detect defects on a display panel using light-field 3D imaging. Without powering the target display panel, we first acquire the high-resolution depth information of defects located inside the transparent layers. We then convert the depth information to the object coordinate system to estimate the physical locations of defects. We automatically classify the types of defects and their layer locations along the depth axis in multiple transparent layers of the display panel. Lastly, our experimental results validate that our method can successfully detect and classify various display defects.
|
|
 |
Actively Tunable Spectral Filter for Compact Hyperspectral Camera using Angle-Sensitive Plasmonic Structures
Myeong-Su Ahn, Jaehun Jeon, Charles Soon Hong Hwang, Daniel S. Jeon,
Min H. Kim, Ki-Hun Jeong
Advanced Materials Technologies
2201482, published on April 4, 2023
|
[PDF][BibTeX] |
| |
Hyperspectral imaging provides enhanced classification and identification of veiled features for diverse biomedical applications such as label-free cancer detection or non-invasive vascular disease diagnostics. However, hyperspectral cameras still have technical limitations in miniaturization due to the inherently complex and bulky configurations of conventional tunable filters. Herein, a compact hyperspectral camera using an active plasmonic tunable filter (APTF) with electrothermally driven spectral modulation for feature-augmented imaging is reported. APTF consists of angle-sensitive plasmonic structures (APS) over an electrothermal MEMS (Microelectromechanical systems) actuator, fabricated by combining nanoimprint lithography, and MEMS fabrication ona 6-inch wafer. APS have a complementary configuration of Au nanohole and nanodisk arrays supported on asilicon nitride membrane. APTF shows a large angular motion at operational voltages of 5–9 VDC for continuous spectral modulation between 820 and 1000 nm (45 nm/V). The compact hyperspectral camera was fully packaged with a linear polarizer, APTF and amonochromatic camera, exhibiting asize of 16 mm (ϕ) × 9.5 mm (h). Feature-augmented images of subcutaneous vein and a fresh fruit have been successfully demonstrated after the hyperspectral reconstruction and spectral feature extraction. This functional camera provides a new compact platform for point-of-care or in vivo hyperspectral imaging in biomedicalapplications.
|
|
 |
Sparse Ellipsometry: Portable Acquisition of Polarimetric SVBRDF and Shape with Unstructured Flash Photography
Inseung Hwang, Daniel S. Jeon, Adolfo Muñoz, Diego Gutierrez, Xin Tong, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2022,
SIGGRAPH Technical Paper Award Honorable Mention
41(4), Aug. 8 - Aug. 11, 2022 |
[PDF][Supple][Code]
[BibTeX] |
| |
Ellipsometry techniques allow to measure polarization information of materials, requiring precise rotations of optical components with different configurations of lights and sensors. This results in cumbersome capture devices, carefully calibrated in lab conditions, and in very long acquisition times, usually in the order of a few days per object. Recent techniques allow to capture polarimetric spatially-varying reflectance information, but limited to a single view, or to cover all view directions, but limited to spherical objects made of a single homogeneous material.We present sparse ellipsometry, a portable polarimetric acquisition method that captures both polarimetric SVBRDF and 3D shape simultaneously. Our handheld device consists of off-the-shelf, fixed optical components. Instead of days, the total acquisition time varies between twenty and thirty minutes per object. We develop a complete polarimetric SVBRDF model that includes diffuse and specular components, as well as single scattering, and devise a novel polarimetric inverse rendering algorithm with data augmentation of specular reflection samples via generative modeling. Our results show a strong agreement with a recent ground-truth dataset of captured polarimetric BRDFs of real-world objects.
|
|
 |
Egocentric Scene Reconstruction From an Omnidirectional Video
Hyeonjoong Jang, Andréas Meuleman, Dahyun Kang, Donggun Kim, Christian Richardt,
Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2022
41(4), Aug. 8 - Aug. 11, 2022 |
[PDF][Supple][Code]
[BibTeX] |
| |
Omnidirectional videos capture environmental scenes effectively, but they have rarely been used for geometry reconstruction. In this work, we propose an egocentric 3D reconstruction method that can acquire scene geometry with high accuracy from a short egocentric omnidirectional video. To this end, we first estimate per-frame depth using a spherical disparity network. We then fuse per-frame depth estimates into a novel spherical binoctree data structure that is specifically designed to tolerate spherical depth estimation errors. By subdividing the spherical space into binary tree and octree nodes that represent spherical frustums adaptively, the spherical binoctree effectively enables egocentric surface geometry reconstruction for environmental scenes while simultaneously assigning high-resolution nodes for closely observed surfaces. This allows to reconstruct an entire scene from a short video captured with a small camera trajectory. Experimental results validate the effectiveness and accuracy of our approach for reconstructing the 3D geometry of environmental scenes from short egocentric omnidirectional video inputs. We further demonstrate various applications using a conventional omnidirectional camera, including novel-view synthesis, object insertion, and relighting of scenes using reconstructed 3D models with texture.
|
|
 |
FloatingFusion: Depth from ToF and Image-stabilized Stereo Cameras
Andreas Meuleman, Hakyeong Kim, James Tompkin, Min H. Kim
Proc. European Conference on Computer Vision (ECCV 2022)
Tel Aviv, Oct. 23 – 27, 2022 |
[PDF][Supple][BibTeX] |
| |
High-accuracy per-pixel depth is vital for computational photography, so smartphones now have multimodal camera systems with time-of-flight (ToF) depth sensors and multiple color cameras. However, producing accurate high-resolution depth is still challenging due to the low resolution and limited active illumination power of ToF sensors. Fusing RGB stereo and ToF information is a promising direction to overcome these issues, but a key problem remains: to provide high-quality 2D RGB images, the main color sensor’s lens is optically stabilized, resulting in an unknown pose for the floating lens that breaks the geometric relationships between the multimodal image sensors. Leveraging ToF depth estimates and a wide-angle RGB camera, we design an automatic calibration technique based on dense 2D/3D matching that can estimate camera extrinsic, intrinsic, and distortion parameters of a stabilized main RGB sensor from a single snapshot. This lets us fuse stereo and ToF cues via a correlation volume. For fusion, we apply deep learning via a real-world training dataset with depth supervision estimated by a neural reconstruction method. For evaluation, we acquire a test dataset using a commercial high-power depth camera and show that our approach achieves higher accuracy than existing baselines.
|
|
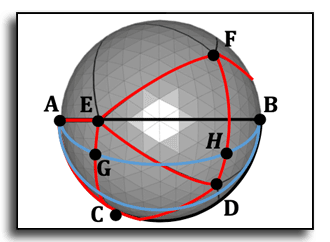 |
Uniform Subdivision of Omnidirectional Camera Space for Efficient Spherical Stereo Matching
Donghun Kang, Hyeonjoong Jang, Jungeon Lee, Chong-Min Kyung, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2022)
New Orleans, USA, Jun. 19 - 24, 2022 |
[PDF][Suppl.][BibTeX] |
| |
Omnidirectional cameras have been used widely to better understand surrounding environments. They are often configured as stereo to estimate depth. However, due to the optics of the fisheye lens, conventional epipolar geometry is inapplicable directly to omnidirectional camera images. Intermediate formats of omnidirectional images, such as equirectangular images, have been used. However, stereo matching performance on these image formats has been lower than the conventional stereo due to severe image distortion near pole regions. In this paper, to address the distortion problem of omnidirectional images, we devise a novel subdivision scheme of a spherical geodesic grid. This enables more isotropic patch sampling of spherical image information in the omnidirectional camera space. By extending the existing equal-arc scheme, our spherical geodesic grid is tessellated with an equal-epiline subdivision scheme, making the cell sizes and in-between distances as uniform as possible, i.e., the arc length of the spherical grid cell’s edges is well regularized. Also, our uniformly tessellated coordinates in a 2D image can be transformed into spherical coordinates via oneto- one mapping, allowing for analytical forward/backward transformation. Our uniform tessellation scheme achieves a higher accuracy of stereo matching than the traditional cylindrical and cubemap-based approaches, reducing the memory footage required for stereo matching by 20%.
|
|
 |
Differentiable Appearance Acquisition from a Flash/No-flash RGB-D Pair
Hyun Jin Ku, Hyunho Ha, Joo Ho Lee, Dahyun Kang, James Tompkin, Min H. Kim
Proc. IEEE International Conference on Computational Photography (ICCP 2022)
Caltech, Pasadena, August 1-3, 2022 |
[PDF][Supple][BibTeX] |
| |
Reconstructing 3D objects in natural environments requires solving the ill-posed problem of geometry, spatially-varying material, and lighting estimation. As such, many approaches impractically constrain to a dark environment, use controlled lighting rigs, or use few handheld captures but suffer reduced quality. We develop a method that uses just two smartphone exposures captured in ambient lighting to reconstruct appearance more accurately and practically than baseline methods. Our insight is that we can use a flash/no-flash RGB-D pair to pose an inverse rendering problem using point lighting. This allows efficient differentiable rendering to optimize depth and normals from a good initialization and so also the simultaneous optimization of diffuse environment illumination and SVBRDF material. We find that this reduces diffuse albedo error by 25%, specular error by 46%, and normal error by 30% against singleand paired-image baselines that use learning-based techniques. Given that our approach is practical for everyday solid objects, we enable photorealistic relighting for mobile photography and easier content creation for augmented reality.
|
|
 |
High-Accuracy Image Formation Model for Coded Aperture Snapshot Spectral Imaging
Lingfei Song, Lizhi Wang, Min H. Kim, Hua Huang
IEEE Transactions on Computational Imaging (TCI)
published in February, 2022 |
[PDF]
[BibTeX] |
| |
Despite advances in display technology, many existing applications rely on psychophysical datasets of human perception gathered using older, sometimes outdated displays. As a result, there exists the underlying assumption that such measurements can be carried over to the new viewing conditions of more modern technology. We have conducted a series of psychophysical experiments to explore contrast sensitivity using a state-of-the-art HDR display, taking into account not only the spatial frequency and luminance of the stimuli but also their surrounding luminance levels. From our data, we have derived a novel surround-aware contrast sensitivity function (CSF), which predicts human contrast sensitivity more accurately. We additionally provide a practical version that retains the benefits of our full model, while enabling easy backward compatibility and consistently producing good results across many existing applications that make use of CSF models. We show examples of effective HDR video compression using a transfer function derived from our CSF, tone-mapping, and improved accuracy in visual difference prediction.
|
|
 |
Modelling Surround-aware Contrast Sensitivity for HDR Displays
Shinyoung Yi, Daniel S. Jeon, Ana Serrano, Se-Yoon Jeong, Hui-Yong Kim,
Diego Gutierrez, Min H. Kim
Computer Graphics Forum (CGF)
published in January, 2022 |
[PDF][Suppl.][Dataset]
[BibTeX] |
| |
Despite advances in display technology, many existing applications rely on psychophysical datasets of human perception gathered using older, sometimes outdated displays. As a result, there exists the underlying assumption that such measurements can be carried over to the new viewing conditions of more modern technology. We have conducted a series of psychophysical experiments to explore contrast sensitivity using a state-of-the-art HDR display, taking into account not only the spatial frequency and luminance of the stimuli but also their surrounding luminance levels. From our data, we have derived a novel surround-aware contrast sensitivity function (CSF), which predicts human contrast sensitivity more accurately. We additionally provide a practical version that retains the benefits of our full model, while enabling easy backward compatibility and consistently producing good results across many existing applications that make use of CSF models. We show examples of effective HDR video compression using a transfer function derived from our CSF, tone-mapping, and improved accuracy in visual difference prediction.
|
|
 |
Edge-aware Bi-directional Diffusion for Dense Depth Estimation from Light Fields
Numair Khan, Min H. Kim, James Tompkin
Proc. British Machine Vision Conference (BMVC) 2021
Virtual, November 22nd - 25th, 2021
|
[PDF][Code][BibTeX] |
| |
We present an algorithm to estimate fast and accurate depth maps from light fields via a sparse set of depth edges and gradients. Our proposed approach is based around the idea that true depth edges are more sensitive than texture edges to local constraints, and so they can be reliably disambiguated through a bidirectional diffusion process. First, we use epipolar-plane images to estimate sub-pixel disparity at a sparse set of pixels. To find sparse points efficiently, we propose an entropy-based refinement approach to a line estimate from a limited set of oriented filter banks. Next, to estimate the diffusion direction away from sparse points, we optimize constraints at these points via our bidirectional diffusion method. This resolves the ambiguity of which surface the edge belongs to and reliably separates depth from texture edges, allowing us to diffuse the sparse set in a depth-edge and occlusion-aware manner to obtain accurate dense depth maps.
|
|
 |
Differentiable Transient Rendering
Shinyoung Yi, Donggun Kim, Kiseok Choi, Adrian Jarabo, Diego Gutierrez, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2021
40(6), Dec. 14 - Dec. 17, 2021 |
[PDF][Supple][Code]
[BibTeX] |
| |
Recent differentiable rendering techniques have become key tools to tackle many inverse problems in graphics and vision. Existing models, however, assume steady-state light transport, i.e., infinite speed of light. While this is a safe assumption for many applications, recent advances in ultrafast imaging leverage the wealth of information that can be extracted from the exact time of flight of light. In this context, physically-based transient rendering allows to efficiently simulate and analyze light transport considering that the speed of light is indeed finite. In this paper, we introduce a novel differentiable transient rendering framework, to help bring the potential of differentiable approaches into the transient regime. To differentiate the transient path integral we need to take into account that scattering events at path vertices are no longer independent; instead, tracking the time of flight of light requires treating such scattering events at path vertices jointly as a multidimensional, evolving manifold. We thus turn to the generalized transport theorem, and introduce a novel \textit{correlated importance} term, which links the time-integrated contribution of a path to its light throughput, and allows us to handle discontinuities in the light and sensor functions. Last, we present results in several challenging scenarios where the time of flight of light plays an important role such as optimizing indices of refraction, non-line-of-sight tracking with nonplanar relay walls, and non-line-of-sight tracking around two corners.
|
|
 |
DeepFormableTag: End-to-end Generation and Recognition of Deformable Fiducial Markers
Mustafa B. Yaldiz, Andreas Meuleman, Hyeonjoong Jang, Hyunho Ha, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2021
40(4), Aug. 9 - Aug. 13, 2021 |
[PDF][Supple][Code]
[BibTeX] |
| |
Fiducial markers have been broadly used to identify objects or embed messages that can be detected by a camera. Primarily, existing detection methods assume that markers are printed on ideally planar surfaces. The size of a message or identification code is limited by the spatial resolution of binary patterns in a marker. Markers often fail to be recognized due to various imaging artifacts of optical/perspective distortion and motion blur. To overcome these limitations, we propose a novel deformable fiducial marker system that consists of three main parts: First, a fiducial marker generator creates a set of free-form color patterns to encode significantly large-scale information in unique visual codes. Second, a differentiable image simulator creates a training dataset of photorealistic scene images with the deformed markers, being rendered during optimization in a differentiable manner. The rendered images include realistic shading with specular reflection, optical distortion, defocus and motion blur, color alteration, imaging noise, and shape deformation of markers. Lastly, a trained marker detector seeks the regions of interest and recognizes multiple marker patterns simultaneously via inverse deformation transformation. The deformable marker creator and detector networks are jointly optimized via the differentiable photorealistic renderer in an end-to-end manner, allowing us to robustly recognize a wide range of deformable markers with high accuracy. Our deformable marker system is capable of decoding 36-bit messages successfully at ~29 fps with severe shape deformation. Results validate that our system significantly outperforms the traditional and data-driven marker methods. Our learning-based marker system opens up new interesting applications of fiducial markers, including cost-effective motion capture of the human body, active 3D scanning using our fiducial markers' array as structured light patterns, and robust augmented reality rendering of virtual objects on dynamic surfaces.
|
|
 |
Single-shot Hyperspectral-Depth Imaging with Learned Diffractive Optics
Seung-Hwan Baek, Hayato Ikoma, Daniel S. Jeon, Yuqi Li, Wolfgang Heidrich, Gordon Wetzstein, Min H. Kim
Proc. IEEE International Conference on Computer Vision (ICCV) 2021
Montreal, Canada & Virtual, Oct 11, 2021 – Oct 17, 2021 |
[PDF][Supple][BibTeX] |
| |
Imaging depth and spectrum have been extensively studied in isolation from each other for decades. Recently, hyperspectral-depth (HS-D) imaging emerges to capture both information simultaneously by combining two different imaging systems; one for depth, the other for spectrum. While being accurate, this combinational approach induces increased form factor, cost, capture time, and alignment/registration problems. In this work, departing from the combinational principle, we propose a compact single-shot monocular HS-D imaging method. Our method uses a diffractive optical element (DOE), the point spread function of which changes with respect to both depth and spectrum. This enables us to reconstruct spectrum and depth from a single captured image. To this end, we develop a differentiable simulator and a neural-network-based reconstruction that are jointly optimized via automatic differentiation. To facilitate learning the DOE, we present a first HS-D dataset by building a benchtop HS-D imager that acquires high-quality ground truth. We evaluate our method with synthetic and real experiments by building an experimental prototype and achieve state-of-the-art HS-D imaging results.
|
|
 |
Modeling Surround-aware Contrast Sensitivity
Shinyoung Yi, Daniel S. Jeon, Ana Serrano, Se-Yoon Jeong, Hui-Yong Kim,
Diego Gutierrez, Min H. Kim
Proc. Eurographics Symposium on Rendering (EGSR) 2021
Saarbrucken, Germany & Virtual, June 29 - July 2, 2021 |
[PDF][Suppl.][Dataset]
[Slides][Code][BibTeX] |
| |
Despite advances in display technology, many existing applications rely on psychophysical datasets of human perception gathered using older, sometimes outdated displays. As a result, there exists the underlying assumption that such measurements can be carried over to the new viewing conditions of more modern technology. We have conducted a series of psychophysical experiments to explore contrast sensitivity using a state-of-the-art HDR display, taking into account not only the spatial frequency and luminance of the stimuli but also their surrounding luminance levels. From our data, we have derived a novel surroundaware contrast sensitivity function (CSF), which predicts human contrast sensitivity more accurately. We additionally provide a practical version that retains the benefits of our full model, while enabling easy backward compatibility and consistently producing good results across many existing applications that make use of CSF models. We show examples of effective HDR video compression using a transfer function derived from our CSF, tone-mapping, and improved accuracy in visual difference prediction.
|
|
 |
Real-Time Sphere Sweeping Stereo from Multiview Fisheye Images
Andreas Meuleman, Hyeonjoong Jang, Daniel S. Jeon, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2021, Oral)
Nashville, Tennessee, USA, June 19--25, 2021 |
[PDF][video][Supple]
[Code]
[BibTeX] |
| |
A set of cameras with fisheye lenses have been used to capture a wide field of view. The traditional scan-line stereo algorithms based on epipolar geometry are directly inapplicable to this non-pinhole camera setup due to optical characteristics of fisheye lenses; hence, existing complete 360° RGB-D imaging systems have rarely achieved real-time performance yet. In this paper, we introduce an efficient sphere-sweeping stereo that can run directly on multiview fisheye images without requiring additional spherical rectification. Our main contributions are: First, we introduce an adaptive spherical matching method that accounts for each input fisheye camera's resolving power concerning spherical distortion. Second, we propose a fast inter-scale bilateral cost volume filtering method that refines distance in noisy and textureless regions with optimal complexity of O(n). It enables real-time dense distance estimation while preserving edges. Lastly, the fisheye color and distance images are seamlessly combined into a complete 360° RGB-D image via fast inpainting of the dense distance map. We demonstrate an embedded 360° RGB-D imaging prototype composed of a mobile GPU and four fisheye cameras. Our prototype is capable of capturing complete 360° RGB-D videos with a resolution of two megapixels at 29 fps. Results demonstrate that our real-time method outperforms traditional omnidirectional stereo and learning-based omnidirectional stereo in terms of accuracy and performance.
|
|
 |
High-Quality Stereo Image Restoration from Double Refraction
Hakyeong Kim, Andreas Meuleman, Daniel S. Jeon, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2021)
Nashville, Tennessee, USA, June 19--25, 2021 |
[PDF][Video][Code][BibTeX] |
| |
Single-shot monocular birefractive stereo methods have been used for estimating sparse depth from double refraction over edges. They also obtain an ordinary-ray (o-ray) image concurrently or subsequently through additional post-processing of depth densification and deconvolution. However, when an extraordinary-ray (e-ray) image is restored to acquire stereo images, the existing methods suffer from very severe restoration artifacts due to a low signal-to-noise ratio of input e-ray image or depth/deconvolution errors. In this work, we present a novel stereo image restoration network that can restore stereo images directly from a double-refraction image. First, we built a physically faithful birefractive stereo imaging dataset by simulating the double refraction phenomenon with existing RGB-D datasets. Second, we formulated a joint stereo restoration problem that accounts for not only geometric relation between o-/e-ray images but also joint optimization of restoring both stereo images. We trained our model with our birefractive image dataset in an end-to-end manner. Our model restores high-quality stereo images directly from double refraction in real-time, enabling high-quality stereo video using a monocular camera. Our method also allows us to estimate dense depth maps from stereo images using a conventional stereo method. We evaluate the performance of our method experimentally and synthetically with the ground truth. Results validate that our stereo image restoration network outperforms the existing methods with high accuracy. We demonstrate several image-editing applications using our high-quality stereo images and dense depth maps.
|
|
 |
NormalFusion: Real-Time Acquisition of Surface Normals for High-Resolution RGB-D Scanning
Hyunho Ha, Joo Ho Lee, Andreas Meuleman, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2021)
Nashville, Tennessee, USA, June 19--25, 2021 |
[PDF][Supple][Video]
[Code]
[BibTeX] |
| |
Multiview shape-from-shading (SfS) has achieved high-detail geometry, but its computation is expensive for solving a multiview registration and an ill-posed inverse rendering problem. Therefore, it has been mainly used for offline methods. Volumetric fusion enables real-time scanning using a conventional RGB-D camera, but its geometry resolution has been limited by the grid resolution of the volumetric distance field and depth registration errors. In this paper, we propose a real-time scanning method that can acquire high-detail geometry by bridging volumetric fusion and multiview SfS in two steps. First, we propose the first real-time acquisition of photometric normals stored in texture space to achieve high-detail geometry. We also introduce geometry-aware texture mapping, which progressively refines geometric registration between the texture space and the volumetric distance field by means of normal texture, achieving real-time multiview SfS. We demonstrate our scanning of high-detail geometry using an RGB-D camera at ~20 fps. Results verify that the geometry quality of our method is strongly competitive with that of offline multi-view SfS methods.
|
|
 |
Differentiable Diffusion for Dense Depth Estimation from Multi-view Images
Numair Khan, Min H. Kim, James Tompkin
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2021)
Nashville, Tennessee, USA, June 19--25, 2021 |
[PDF][Video][Code][BibTeX] |
| |
We present a method to estimate dense depth by optimizing a sparse set of points such that their diffusion into a depth map minimizes a multi-view reprojection error from RGB supervision.
We optimize point positions, depths, and weights with respect to the loss by differential splatting that models points as Gaussians with analytic transmittance.
Further, we develop an efficient optimization routine that can simultaneously optimize the 50k+ points required for complex scene reconstruction.
We validate our routine using ground truth data and show high reconstruction quality.
Then, we apply this to light field and wider baseline images via self supervision, and show improvements in both average and outlier error for depth maps diffused from inaccurate sparse points.
Finally, we compare qualitative and quantitative results to image processing and deep learning methods.
|
|
 |
View-dependent Scene Appearance Synthesis using Inverse Rendering from Light Fields
Dahyun Kang, Daniel S. Jeon, Hakyeong Kim, Hyeonjoong Jang, Min H. Kim
Proc. IEEE International Conference on Computational Photography (ICCP 2021)
Haifa, Israel, May 23--25, 2021 |
[PDF][Supple][BibTeX] |
| |
In order to enable view-dependent appearance synthesis from the light fields of a scene, it is critical to evaluate the geometric relationships between light and view over surfaces in the scene with high accuracy. Perfect diffuse reflectance is commonly assumed to estimate geometry from light fields via multiview stereo. However, this diffuse surface assumption is invalid with real-world objects. Geometry estimated from light fields is severely degraded over specular surfaces. Additional scene-scale 3D scanning based on active illumination could provide reliable geometry, but it is sparse and thus still insufficient to calculate view-dependent appearance, such as specular reflection, in geometry-based view synthesis. In this work, we present a practical solution of inverse rendering to enable view-dependent appearance synthesis, particularly of scene scale. We enhance the scene geometry by eliminating the specular component, thus enforcing photometric consistency. We then estimate spatially-varying parameters of diffuse, specular, and normal components from wide-baseline light fields. To validate our method, we built a wide-baseline light field imaging prototype that consists of 32 machine vision cameras with fisheye lenses of 185 degrees that cover the forward hemispherical appearance of scenes. We captured various indoor scenes, and results validate that our method can estimate scene geometry and reflectance parameters with high accuracy, enabling view-dependent appearance synthesis at scene scale with high fidelity, i.e., specular reflection changes according to a virtual viewpoint.
|
|
 |
View-consistent 4D Light Field Depth Estimation
Numair Khan, Min H. Kim, James Tompkin
Proc. British Machine Vision Conference (BMVC) 2020
Virtual, September 7--10, 2020
|
[PDF][Video][Code][BibTeX] |
| |
To estimate appearance parameters, traditional SVBRDF acquisition methods require multiple input images to be captured with
various angles of light and camera, followed by a post-processing step. For this reason, subjects have been limited to static
scenes, or a multiview system is required to capture dynamic objects. In this paper, we propose a simultaneous acquisition
method of SVBRDF and shape allowing us to capture the material appearance of deformable objects in motion using a single
RGBD camera. To do so, we progressively integrate photometric samples of surfaces in motion in a volumetric data structure
with a deformation graph. Then, building upon recent advances of fusion-based methods, we estimate SVBRDF parameters in
motion. We make use of a conventional RGBD camera that consists of the color and infrared cameras with active infrared illumination.
The color camera is used for capturing diffuse properties, and the infrared camera-illumination module is employed
for estimating specular properties by means of active illumination. Our joint optimization yields complete material appearance
parameters. We demonstrate the effectiveness of our method with extensive evaluation on both synthetic and real data that
include various deformable objects of specular and diffuse appearance.
|
|
 |
Progressive Acquisition of SVBRDF and Shape in Motion
Hyunho Ha, Seung-Hwan Baek, Giljoo Nam, Min H. Kim
Computer Graphics Forum (CGF), presented at Eurographics 2021
published on Aug. 08, 2020.
|
[PDF][Supple1][BibTeX] |
| |
To estimate appearance parameters, traditional SVBRDF acquisition methods require multiple input images to be captured with
various angles of light and camera, followed by a post-processing step. For this reason, subjects have been limited to static
scenes, or a multiview system is required to capture dynamic objects. In this paper, we propose a simultaneous acquisition
method of SVBRDF and shape allowing us to capture the material appearance of deformable objects in motion using a single
RGBD camera. To do so, we progressively integrate photometric samples of surfaces in motion in a volumetric data structure
with a deformation graph. Then, building upon recent advances of fusion-based methods, we estimate SVBRDF parameters in
motion. We make use of a conventional RGBD camera that consists of the color and infrared cameras with active infrared illumination.
The color camera is used for capturing diffuse properties, and the infrared camera-illumination module is employed
for estimating specular properties by means of active illumination. Our joint optimization yields complete material appearance
parameters. We demonstrate the effectiveness of our method with extensive evaluation on both synthetic and real data that
include various deformable objects of specular and diffuse appearance.
|
|
 |
Image-Based Acquisition and Modeling of Polarimetric Reflectance
Seung-Hwan Baek, Tizian Zeltner, Hyun Jin Ku, Inseung Hwang, Xin Tong, Wenzel Jakob, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2020
39(4), Jul. 19 - Jul. 23, 2020
|
[PDF][Supple1][Supple2]
[Supple3][BibTeX] |
| |
Realistic modeling of the bidirectional reflectance distribution function (BRDF) of scene objects is a vital prerequisite for any type of physically based rendering. In the last decades, the availability of databases containing real-world material measurements has fueled considerable innovation in the development of such models. However, previous work in this area was mainly focused on increasing the visual realism of images, and hence ignored the effect of scattering on the polarization state of light, which is normally imperceptible to the human eye. Existing databases thus only capture scattered flux, or they are too directionally sparse (e.g.,~in-plane) to be usable for simulation.
While subtle to human observers, polarization is easily perceived by any optical sensor (e.g., using polarizing filters), providing a wealth of additional information about shape and material properties of the object under observation. Given the increasing application of rendering in the solution of inverse problems via analysis-by-synthesis and differentiation, the ability to realistically model polarized radiative transport is thus highly desirable.
Polarization depends on the wavelength of the spectrum, and thus we provide the first polarimetric BRDF (pBRDF) dataset that captures the polarimetric properties of real-world materials over the full angular domain, and at multiple wavelengths. Acquisition of such reflectance data is challenging due to the extremely large space of angular, spectral, and polarimetric configurations that must be observed, and we propose a scheme combining image-based acquisition with spectroscopic ellipsometry to perform measurements in a realistic amount of time. This process yields raw Mueller matrices, which we subsequently transform into Rusinkiewicz-parameterized pBRDFs that can be used for rendering.
Our dataset provides 25 isotropic pBRDFs spanning a wide range of appearances: diffuse/specular, metallic/dielectric, rough/smooth, and different color albedos, captured in five wavelength ranges covering the visible spectrum. We demonstrate usage of our data-driven pBRDF model in a physically based renderer that accounts for polarized interreflection, and we investigate the relationship of polarization and material appearance, providing insights into the behavior of characteristic real-world pBRDFs.
|
|
 |
TextureFusion: High-Quality Texture Acquisition for Real-Time RGB-D Scanning
Joo Ho Lee, Hyunho Ha, Yue Dong, Xin Tong, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2020, Oral)
Best Paper Finalist
Seattle, WA, USA, June 14--19, 2020
|
[PDF][Slides][Code][BibTeX] |
| |
Real-time RGB-D scanning has become widely used to scan 3D objects progressively with a hand-held sensor. Existing online methods restore color information per voxel so that its quality is often limited by the tradeoff between spatial resolution and performance. They often suffer from blur artifacts in the captured texture. Traditional offline texture mapping methods with non-rigid warping assume that the reconstructed geometry and all views are known, and the optimization takes a long time, which prevents them from real-time applications. In this work, we propose a progressive texture-fusion method specifically designed for real-time RGB-D scanning. To this end, we first devise a novel texture-tile voxel grid, where texture tiles are embedded in the voxel grid of the signed distance function, allowing for high-resolution texture mapping on the low-resolution geometry volume. Instead of using expensive mesh parameterization, we associate vertexes of implicit geometry directly with texture coordinates. Second, we introduce real-time texture warping that applies spatially-varying perspective mapping to input images to efficiently mitigate the mismatch between the intermediate geometry and the current input view. It allows us to enhance the quality of texture over time while updating the geometry in real-time. Results demonstrate that the quality of our real-time texture mapping is highly competitive to that of existing offline texture warping methods. Our method is also capable of being integrated into existing RGB-D scanning frameworks.
|
|
 |
Single-shot Monocular RGB-D Imaging using Uneven Double Refraction
Andreas Meuleman, Seung-Hwan Baek, Felix Heide, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2020, Oral)
Seattle, WA, USA, June 14--19, 2020
|
[PDF][Slides][Supple_v2]
[Code][BibTeX] |
| |
Cameras that capture color and depth information have become an essential imaging modality for applications in robotics, autonomous driving, virtual, and augmented reality. Existing RGB-D cameras rely on multiple sensors or active illumination with specialized sensors. In this work, we propose a method for monocular single-shot RGB-D imaging. Instead of learning depth from single-image depth cues, we revisit double-refraction imaging using a birefractive medium, measuring depth as the displacement of differently refracted images superimposed in a single capture. However, existing double-refraction methods are orders of magnitudes too slow to be used in real-time applications, e.g., in robotics, and provide only inaccurate depth due to correspondence ambiguity in double reflection.
We resolve this ambiguity optically by leveraging the orthogonality of the two linearly polarized rays in double refraction -- introducing uneven double refraction by adding a linear polarizer to the birefractive medium.
Doing so makes it possible to develop a real-time method for reconstructing sparse depth and color simultaneously in real-time.
We validate the proposed method, both synthetically and experimentally, and demonstrate 3D object detection and photographic applications.
|
|
 |
Single-shot Acquisition of Cylindrical Mesostructure Normals using Diffuse Illumination
Inseung Hwang, Daniel S. Jeon, Min H. Kim
Proc. International Conference on Computer Vision Theory and Applications (VISAPP 2020)
Valletta, Malta, February 27–29, 2020
|
[PDF][BibTeX] |
| |
Capturing high-quality surface normals is critical to acquire the surface geometry of mesostructures, such as
hair and metal wires with high resolution. Existing image-based acquisition methods have assumed a specific
type of surface reflectance. The shape-from-shading approach, a.k.a. photometric stereo, makes use of the
shading information by a point light, assuming that surfaces are perfectly diffuse. The shape-from-specularity
approach captures specular reflection densely, assuming that surfaces are overly smooth. These existing methods
often fail, however, due to the difference between the presumed and the actual reflectance of real-world
objects. Also, these existing methods require multiple images with different light vectors. In this work, we
present a single-shot normal acquisition method, designed especially for cylindrical mesostructures on a nearflat
geometry. We leverage diffuse illumination to eliminate the reflectance assumption. We then propose a
local shape-from-intensity approach combined with local orientation detection. We conducted several experiments
with synthetic and real objects. Quantitative and qualitative results validate that our method can capture
surface normals of cylindrical mesostructures with high accuracy.
|
|
 |
Extreme View Synthesis
Inchang Choi, Orazio Gallo, Alejandro Troccoli, Min H. Kim, Jan Kautz
Proc. IEEE International Conference on Computer Vision (ICCV 2019, Oral)
Seoul, Korea, Oct. 27–-Nov. 2, 2019
|
[PDF][Supple][BibTeX] |
| |
We present a solution for novel view extrapolation that works even when the number of input images is small---as few as two. In this context, occlusions and depth uncertainty are two of the most pressing issues, and worsen as the degree of extrapolation increases. We follow the traditional paradigm of performing depth-based warping and refinement, enhanced with a few key improvements. First, we estimate a depth probability volume for the novel view rather than just a single depth value for each pixel. This allows us to leverage depth uncertainty in challenging regions, such as depth discontinuities. After using it to get an initial estimate of the novel view, we explicitly combine learned image priors and the depth uncertainty to synthesize a refined image with less artifacts. Our method is the first to show visually pleasing results for baseline magnifications of up to 30 times.
|
|
 |
View-consistent 4D Light Field Superpixel Segmentation
Numair Khan, Qian Zhang, Lucas Kasser, Henry Stone, Min H. Kim, James Tompkin
Proc. IEEE International Conference on Computer Vision (ICCV 2019, Oral)
Seoul, Korea, Oct. 27–-Nov. 2, 2019
|
[PDF][Code][Supple.]
[BibTeX] |
| |
Many 4D light field processing applications rely on superpixel segmentation, for which occlusion-aware view consistency is important. Yet, existing methods often enforce consistency by propagating clusters from a central view only, which can lead to inconsistent superpixels for non-central views. Our proposed approach combines an occlusion-aware angular segmentation in horizontal and vertical the epipolar plane image (EPI) spaces with an occlusion-aware clustering and propagation step across all views. Qualitative video demonstrations show that this helps to remove flickering and inconsistent boundary shapes versus the state-of-the-art LFSP approach, and quantitative metrics reflect these findings with improved self similarity and number of labels per pixel scores.
|
 |
Fast Omnidirectional Depth Densification
Hyeonjoong Jang, Daniel S. Jeon, Hyunho Ha, Min H. Kim
Proc. International Symposium on Visual Computing (ISVC 2019, Oral)
Lake Tahoe, Nevada, USA, October 7--9, 2019
|
[PDF][BibTeX] |
| |
Omnidirectional cameras are commonly equipped with fisheye-lenses to capture 360-degree visual information, and severe spherical projective distortion occurs when a 360-degree image is stored as a two-dimensional image array. As a consequence, traditional depth estimation methods are not directly applicable to omnidirectional cameras. Dense depth estimation for omnidirectional imaging has been achieved by applying several offline processes, such as patch-matching, optical flow, and convolutional propagation filtering, resulting in additional heavy computation. No dense depth estimation for real-time applications is available yet. In response, we propose an efficient depth densification method designed for omnidirectional imaging to achieve 360-degree dense depth video with an omnidirectional camera. First, our method takes sparse depth estimates as input with a conventional simultaneous localization and mapping (SLAM) method. We then introduce a novel spherical pull-push method by devising a joint spherical pyramid for color and depth, based on multi-level icosahedron subdivision surfaces. This allows us to propagate the sparse depth continuously over 360-degree angles efficiently in an edge-aware manner. The results demonstrate that our real-time densification method is comparable to state-of-the-art offline methods in terms of per-pixel depth accuracy. Combining our depth densification with a conventional SLAM allows us to capture real-time 360-degree RGB-D video with a single omnidirectional camera.
|
|
 |
Light-weight Novel View Synthesis for Casual Multiview Photography
Inchang Choi, Yeong Beum Lee, Dae R. Jeong, Insik Shin, Min H. Kim
Proc. International Symposium on Visual Computing (ISVC 2019, Oral)
Lake Tahoe, Nevada, USA, October 7--9, 2019
|
[PDF][BibTeX] |
| |
Traditional view synthesis for image-based rendering requires various processes: camera synchronization with professional equipment, geometric calibration, multiview stereo, and surface reconstruction, resulting in heavy computation, in addition to manual user interactions throughout these processes. Therefore, view synthesis has been available exclusively for professional users. In this paper, we address these expensive costs to enable view synthesis for casual users even with mobile-phone cameras. We assume that casual users take multiple photographs using their phone-cameras, which are used for view synthesis. First, without relying on any expensive synchronization hardware, our method can capture synchronous multiview photographs by utilizing a wireless network protocol. Second, our method provides light-weight image-based rendering on the mobile phone, where heavy computational processes, such as estimating geometry proxies, alpha mattes, and inpainted textures, are processed by a server to be shared in an interactable time. Finally, it allows us to render novel view synthesis along a virtual camera path on the mobile devices, enabling bullet-time photography from casual multiview captures.
|
|
 |
Compact Snapshot Hyperspectral Imaging with Diffracted Rotation
Daniel S. Jeon, Seung-Hwan Baek, Shinyoung Yi, Qiang Fu, Xiong Dun, Wolfgang Heidrich, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2019
38(4), Jul. 28 - Aug. 1, 2019, pp. 117:1--13
|
[PDF][Supple.][BibTeX] |
| |
Traditional snapshot hyperspectral imaging systems include various optical elements: a dispersive optical element (prism), a coded aperture, several relay lenses, and an imaging lens, resulting in an impractically large form factor. We seek an alternative, minimal form factor of snapshot spectral imaging based on recent advances in diffractive optical technology. We there- upon present a compact, diffraction-based snapshot hyperspectral imaging method, using only a novel diffractive optical element (DOE) in front of a conventional, bare image sensor. Our diffractive imaging method replaces the common optical elements in hyperspectral imaging with a single optical element. To this end, we tackle two main challenges: First, the traditional diffractive lenses are not suitable for color imaging under incoherent illu- mination due to severe chromatic aberration because the size of the point spread function (PSF) changes depending on the wavelength. By leveraging this wavelength-dependent property alternatively for hyperspectral imag- ing, we introduce a novel DOE design that generates an anisotropic shape of the spectrally-varying PSF. The PSF size remains virtually unchanged, but instead the PSF shape rotates as the wavelength of light changes. Sec- ond, since there is no dispersive element and no coded aperture mask, the ill-posedness of spectral reconstruction increases significantly. Thus, we pro- pose an end-to-end network solution based on the unrolled architecture of an optimization procedure with a spatial-spectral prior, specifically designed for deconvolution-based spectral reconstruction. Finally, we demonstrate hyperspectral imaging with a fabricated DOE attached to a conventional DSLR sensor. Results show that our method compares well with other state- of-the-art hyperspectral imaging methods in terms of spectral accuracy and spatial resolution, while our compact, diffraction-based spectral imaging method uses only a single optical element on a bare image sensor.
|
|
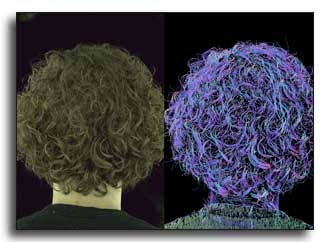 |
Strand-accurate Multi-view Hair Capture
Giljoo Nam, Chenglei Wu, Min H. Kim, Yaser Sheikh
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2019, Oral)
Long Beach, CA, USA, June 16--20, 2019
|
[PDF][BibTeX] |
| |
Hair is one of the most challenging objects to reconstruct due to its micro-scale structure and a large number of repeated strands with heavy occlusions. In this paper, we present the first method to capture high-fidelity hair geometry with strand-level accuracy. Our method takes three stages to achieve this. In the first stage, a new multi-view stereo method with a slanted support line is proposed to solve the hair correspondences between different views. In detail, we contribute a novel cost function consisting of both photo-consistency term and geometric term that reconstructs each hair pixel as a 3D line. By merging all the depth maps, a point cloud, as well as local line directions for each point, is obtained. Thus, in the second stage, we feature a novel strand reconstruction method with the mean-shift to convert the noisy point data to a set of strands. Lastly, we grow the hair strands with multi-view geometric constraints to elongate the short strands and recover the missing strands, thus significantly increasing the reconstruction completeness. We evaluate our method on both synthetic data and real captured data, showing that our method can reconstruct hair strands with sub-millimeter accuracy.
|
|
 |
Hyperspectral Image Reconstruction Using a Deep Spatial-Spectral Prior
Lizhi Wang, Chen Sun, Ying Fu, Min H. Kim, Huang Hua
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2019)
Long Beach, CA, USA, June 16--20, 2019
|
[PDF][BibTeX] |
| |
Regularization is a fundamental technique to solve an ill-posed optimization problem robustly and is essential to reconstruct compressive hyperspectral images. Various hand-crafted priors have been employed as a regularizer but are often insufficient to handle the wide variety of spectra of natural hyperspectral images, resulting in poor reconstruction quality. Moreover, the prior-regularized optimization requires manual tweaking of its weight parameters to achieve a balance between the spatial and spectral fidelity of result images. In this paper, we present a novel hyperspectral image reconstruction algorithm that substitutes the traditional hand-crafted prior with a data-driven prior, based on an optimization-inspired network. Our method consists of two main parts: First, we learn a novel datadriven prior that regularizes the optimization problem with a goal to boost the spatial-spectral fidelity. Our data-driven prior learns both local coherence and dynamic characteristics of natural hyperspectral images. Second, we combine our regularizer with an optimization-inspired network to overcome the heavy computation problem in the traditional iterative optimization methods. We learn the complete parameters in the network through end-to-end training, enabling robust performance with high accuracy. Extensive simulation and hardware experiments validate the superior performance of our method over the state-of-theart methods.
|
|
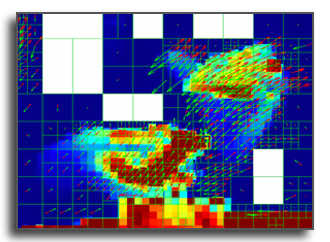 |
Real-time HDR Video Tone Mapping using High Efficiency Video Coding
Mingyun Kang, Joo Ho Lee, Inchang Choi, Min H. Kim
Proc. IEEE International Conference on Image Processing (ICIP 2019)
Taipei, Taiwan, September 22--25, 2019
|
[PDF][BibTeX] |
| |
High-dynamic-range (HDR) video streams have been delivered through high efficiency video coding (HEVC). HDR video tone mapping is additionally required but is operated separately to adjust the content’s dynamic range for each display device. HDR video tone mapping and HEVC encoding share common computational processes for spatial and temporal coherence in a video stream; however, they have been developed and implemented independently with their own computational budgets. In this work, we propose a practical HDR video tone-mapping method that combines two overlapping computational blocks in HDR video tone-mapping and HEVC compression frameworks with the objective of achieving real-time HDR video tone mapping. We utilize precomputed coding blocks and motion vectors so as to achieve spatial and temporal coherence of HDR video tonemapping in the decoding stage, even without introducing substantial computational cost. Results demonstrate that our method can achieve real-time performance without compromising the video quality, which is highly comparable to that of state-of-the-art video tone-mapping methods.
|
|
 |
PaperCraft3D: Paper-Based 3D Modeling and Scene Fabrication
Patrick Paczkowski, Julie Dorsey, Holly Rushmeier, Min H. Kim
IEEE Transactions on Visualization and Computer Graphics (TVCG),
presented at the i3D conference 2019.
pages 1717--1731, Apr. 1, 2019
|
[PDF][BibTeX][Video] |
| |
A 3D modeling system with all-inclusive functionality is too demanding for a casual 3D modeler to learn. There has been a shift towards more approachable systems, with easy-to-learn, intuitive interfaces. However, most modeling systems still employ mouse and keyboard interfaces, despite the ubiquity of tablet devices and the benefits of multi-touch interfaces. We introduce an alternative 3D modeling and fabrication paradigm using developable surfaces, inspired by traditional papercrafting, and we implement it as a complete system designed for a multi-touch tablet, allowing a user to fabricate 3D scenes. We demonstrate the modeling and fabrication process of assembling complex 3D scenes from a collection of simpler models, in turn shaped through operations applied to virtual paper. Our fabrication method facilitates the assembly of the scene with real paper by automatically converting scenes into a series of cutouts with appropriately added fiducial markers and supporting structures. Our system assists users in creating occluded supporting structures to help maintain the spatial and rigid properties of a scene without compromising its aesthetic qualities. We demonstrate several 3D scenes modeled and fabricated in our system, and evaluate the faithfulness of our fabrications relative to their virtual counterparts and 3D-printed fabrications.
|
|
 |
Non-local Haze Propagation with an Iso-Depth Prior
Incheol Kim, Min H. Kim
Computer Vision, Imaging and Computer Graphics – Theory and Applications
in a series of Springer Communications in Computer and Information Science
Jan. 23 2019, pp. 213--238
|
[PDF][BibTeX][Supple.][Site] |
| |
The primary challenge for removing haze from a single image is lack of decomposition cues between the original light transport and airlight scattering in a scene. Many dehazing algorithms start from an assumption on natural image statistics to estimate airlight from sparse cues. The sparsely estimated airlight cues need to be propagated according to the local density of airlight in the form of a transmission map, which allows us to obtain a haze-free image by subtracting airlight from the hazy input. Traditional airlight-propagation methods rely on ordinary regularization on a grid random field, which often results in isolated haze artifacts when they fail in estimating local density of airlight properly. In this work, we propose a non-local regularization method for dehazing by combining Markov random fields (MRFs) with nearest-neighbor fields (NNFs) extracted from the hazy input using the PatchMatch algorithm. Our method starts from the insightful observation that the extracted NNFs can associate pixels at the similar depth. Since regional haze in the atmosphere is correlated with its depth, we can allow propagation across the iso-depth pixels with the MRF-based regularization problem with the NNFs. Our results validate how our method can restore a wide range of hazy images of natural landscape clearly without suffering from haze isolation artifacts. Also, our regularization method is directly applicable to various dehazing methods.
|
|
 |
Practical SVBRDF Acquisition of 3D Objects with Unstructured Flash Photography
Giljoo Nam, Joo Ho Lee, Diego Gutierrez, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2018
37(6), Dec. 4-7, 2018, pp. 267:1--12
|
[PDF][BibTeX][Supp.][Video] |
| |
Capturing spatially-varying bidirectional reflectance distribution functions (SVBRDFs) of 3D objects with just a single, hand-held camera (such as an off-the-shelf smartphone or a DSLR camera) is a difficult, open problem. Previous works are either limited to planar geometry, or rely on previously scanned 3D geometry, thus limiting their practicality. There are several technical challenges that need to be overcome: First, the built-in flash of a camera is almost colocated with the lens, and at a fixed position; this severely hampers sampling procedures in the light-view space. Moreover, the near-field flash lights the object partially and unevenly. In terms of geometry, existing multiview stereo techniques assume diffuse reflectance only, which leads to overly smoothed 3D reconstructions, as we show in this paper. We present a simple yet powerful framework that removes the need for expensive, dedicated hardware, enabling practical acquisition of SVBRDF information from real-world, 3D objects with a single, off-the-shelf camera with a built-in flash. In addition, by removing the diffuse reflection assumption and leveraging instead such SVBRDF information, our method outputs high-quality 3D geometry reconstructions, including more accurate high-frequency details than state-of-the-art multiview stereo techniques. We formulate the joint reconstruction of SVBRDFs, shading normals, and 3D geometry as a multi-stage, iterative inverse-rendering reconstruction pipeline. Our method is also directly applicable to any existing multiview 3D reconstruction technique. We present results of captured objects with complex geometry and reflectance; we also validate our method numerically against other existing approaches that rely on dedicated hardware, additional sources of information, or both.
|
|
 |
Simultaneous Acquisition of Polarimetric SVBRDF and Normals
Seung-Hwan Baek, Daniel S. Jeon, Xin Tong, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2018
37(6), Dec. 4-7, 2018, pp. 268:1--15
|
[PDF][BibTeX][Supp.#1]
[Supp.#2][Video] |
| |
Capturing appearance often requires dense sampling in light-view space, which is often achieved in specialized, expensive hardware setups. With the aim of realizing a compact acquisition setup without multiple angu- lar samples of light and view, we sought to leverage an alternative optical property of light, polarization. To this end, we capture a set of polarimetric images with linear polarizers in front of a single projector and camera to obtain the appearance and normals of real-world objects. We encountered two technical challenges: First, no complete polarimetric BRDF model is available for modeling mixed polarization of both specular and diffuse reflec- tion. Second, existing polarization-based inverse rendering methods are not applicable to a single local illumination setup since they are formulated with the assumption of spherical illumination. To this end, we first present a com- plete polarimetric BRDF (pBRDF) model that can define mixed polarization of both specular and diffuse reflection. Second, by leveraging our pBRDF model, we propose a novel inverse-rendering method with joint optimization of pBRDF and normals to capture spatially-varying material appearance: per-material specular properties (including the refractive index, specular roughness and specular coefficient), per-pixel diffuse albedo and normals. Our method can solve the severely ill-posed inverse-rendering problem by carefully accounting for the physical relationship between polarimetric appearance and geometric properties. We demonstrate how our method overcomes limited sampling in light-view space for inverse rendering by means of polarization.
|
|
 |
Practical Multiple Scattering for Rough Surfaces
Joo Ho Lee, Adrian Jarabo, Daniel S. Jeon, Diego Gutierrez, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2018
37(6), Dec. 4-7, 2018, pp. 275:1--12
|
[PDF][BibTeX][Supp.] |
| |
Microfacet theory concisely models light transport over rough surfaces. Specular reflection is the result of single mirror reflections on each facet, while exact computation of multiple scattering is either neglected, or modeled using costly importance sampling techniques. Practical but accurate simulation of multiple scattering in microfacet theory thus remains an open challenge. In this work, we revisit the traditional V-groove cavity model and derive an analytical, cost-effective solution for multiple scattering in rough surfaces. Our kaleidoscopic model is made up of both real and virtual Vgrooves, and allows us to calculate higher-order scattering in the microfacets in an analytical fashion.We then extend our model to include nonsymmetric grooves, allowing for additional degrees of freedom on the surface geometry, improving multiple reflections at grazing angles with backward compatibility to traditional normal distribution functions. We validate the accuracy of our model against ground-truth Monte Carlo simulations, and demonstrate its flexibility on anisotropic and textured materials. Our model is analytical, does not introduce significant cost and variance, can be seamless integrated in any rendering engine, preserves reciprocity and energy conservation, and is suitable for bidirectional methods.
|
|
 |
Xenos Peckii Vision Inspires an Ultrathin Digital Camera
Dongmin Keum, Kyung-Won Jang, Daniel S. Jeon, Charles S. Hwang, Elke K. Buschbeck, Min H. Kim, Ki-Hun Jeong
Nature Publishing Group (NPG), Light: Science & Applications
7:80(1), Oct. 24, 2018.
|
[PDF][Site][BibTeX] |
| |
Increased demand for compact devices leads to rapid development of miniaturized digital cameras. However, conventional camera modules contain multiple lenses along the optical axis to compensate for optical aberrations that introduce technical challenges in reducing the total thickness of the camera module. Here, we report an ultrathin digital camera inspired by the vision principle of Xenos peckii, an endoparasite of paper wasps. The male Xenos peckii has an unusual visual system that exhibits distinct benefits for high resolution and high sensitivity, unlike the compound eyes found in most insects and some crustaceans. The biologically inspired camera features a sandwiched configuration of concave microprisms, microlenses, and pinhole arrays on a flat image sensor. The camera shows a field-of-view (FOV) of 68 degrees with a diameter of 3.4 mm and a total track length of 1.4 mm. The biologically inspired camera offers a new opportunity for developing ultrathin cameras in medical, industrial, and military fields.
|
|
 |
Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior
Daniel S. Jeon, Seung-Hwan Baek, Inchang Choi, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2018)
Salt Lake City, USA, June 18, 2018
|
[PDF][BibTeX][Supp.] |
| |
We present a novel method that can enhance the spatial resolution of stereo images using a parallax prior. While traditional stereo imaging has focused on estimating depth from stereo images, our method utilizes stereo images to enhance spatial resolution instead of estimating disparity. The critical challenge for enhancing spatial resolution from stereo images: how to register corresponding pixels with subpixel accuracy. Since disparity in traditional stereo imaging is calculated per pixel, it is directly inappropriate for enhancing spatial resolution. We, therefore, learn a parallax prior from stereo image datasets by jointly training two-stage networks. The first network learns how to enhance the spatial resolution of stereo images in luminance, and the second network learns how to reconstruct a high-resolution color image from high-resolution luminance and chrominance of the input image. Our two-stage joint network enhances the spatial resolution of stereo images significantly more than single-image super-resolution methods. The proposed method is directly applicable to any stereo depth imaging methods, enabling us to enhance the spatial resolution of stereo images.
|
|
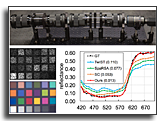 |
High-Quality Hyperspectral Reconstruction Using a Spectral Prior
Inchang Choi, Daniel S. Jeon, Giljoo Nam, Diego Gutierrez, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2017
36(6), Nov. 27-30, 2017, pp. 218:1--13
|
[PDF][BibTeX][Supp.]
[Dataset][Codes] |
| |
We present a novel hyperspectral image reconstruction algorithm, which overcomes the long-standing tradeoff between spectral accuracy and spatial resolution in existing compressive imaging approaches. Our method consists of two steps: First, we learn nonlinear spectral representations from real-world hyperspectral datasets; for this, we build a convolutional autoencoder, which allows reconstructing its own input through its encoder and decoder networks. Second, we introduce a novel optimization method, which jointly regularizes the fidelity of the learned nonlinear spectral representations and the sparsity of gradients in the spatial domain, by means of our new fidelity prior. Our technique can be applied to any existing compressive imaging architecture, and has been thoroughly tested both in simulation, and by building a prototype hyperspectral imaging system. It outperforms the state-of-the-art methods from each architecture, both in terms of spectral accuracy and spatial resolution, while its computational complexity is reduced by two orders of magnitude with respect to sparse coding techniques. Moreover, we present two additional applications of our method: hyperspectral interpolation and demosaicing. Last, we have created a new high-resolution hyperspectral dataset containing sharper images of more spectral variety than existing ones, available through our project website.
|
|
| |
We present a novel, compact single-shot hyperspectral imaging method. It enables capturing hyperspectral images using a conventional DSLR camera equipped with just an ordinary refractive prism in front of the camera lens. Our computational imaging method reconstructs the full spectral information of a scene from dispersion over edges. Our setup requires no coded aperture mask, no slit, and no collimating optics, which are necessary for traditional hyperspectral imaging systems. It is thus very cost-effective, while still highly accurate. We tackle two main problems: First, since we do not rely on collimation, the sensor records a projection of the dispersion information, distorted by perspective. Second, available spectral cues are sparse, present only around object edges. We formulate an image formation model that can predict the perspective projection of dispersion, and a reconstruction method that can estimate the full spectral information of a scene from sparse dispersion information. Our results show that our method compares well with other state-of-the-art hyperspectral imaging systems, both in terms of spectral accuracy and spatial resolution, while being orders of magnitude cheaper than commercial imaging systems.
|
|
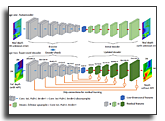 |
DeepToF: Off-the-Shelf Real-Time Correction of Multipath Interference in Time-of-Flight Imaging
Julio Marco, Quercus Hernandez, Adolfo Munoz, Yue Dong, Adrian Jarabo, Min H. Kim,
Xin Tong, Diego Gutierrez
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2017
36(6), Nov. 27-30, 2017, pp. 219:1--12
|
[PDF][BibTeX] |
| |
Time-of-flight (ToF) imaging has become a widespread technique for depth estimation, allowing affordable off-the-shelf cameras to provide depth maps in real time. However, multipath interference (MPI) resulting from indirect illumination significantly degrades the captured depth. Most previous works have tried to solve this problem by means of complex hardware modifications or costly computations. In this work, we avoid these approaches and propose a new technique to correct errors in depth caused by MPI, which requires no camera modifications and takes just 10 milliseconds per frame. Our observations about the nature of MPI suggest that most of its information is available in image space; this allows us to formulate the depth imaging process as a spatially-varying convolution and use a convolutional neural network to correct MPI errors. Since the input and output data present similar structure, we base our network on an autoencoder, which we train in two stages. First, we use the encoder (convolution filters) to learn a suitable basis to represent MPI-corrupted depth images; then, we train the decoder (deconvolution filters) to correct depth from synthetic scenes, generated by using a physically-based, time-resolved renderer. This approach allows us to tackle a key problem in ToF, the lack of ground-truth data, by using a large-scale captured training set with MPI-corrupted depth to train the encoder, and a smaller synthetic training set with ground truth depth to train the decoder stage of the network. We demonstrate and validate our method on both synthetic and real complex scenarios, using an off-the-shelf ToF camera, and with only the captured, incorrect depth as input.
|
|
 |
Reconstructing Interlaced High-Dynamic-Range Video using Joint Learning
Inchang Choi, Seung-Hwan Baek, and Min H. Kim
IEEE Transactions on Image Processing (TIP)
26(11), Nov. 2017, pp. 5353 - 5366
|
[PDF][BibTeX][Supp.]
[Video][Site] |
| |
For extending the dynamic range of video, it is a common practice to capture multiple frames sequentially with different exposures and combine them to extend the dynamic range of each video frame. However, this approach results in typical ghosting artifacts due to fast and complex motion in nature. As an alternative, video imaging with interlaced exposures has been introduced to extend the dynamic range. However, the interlaced approach has been hindered by jaggy artifacts and sensor noise, leading to concerns over image quality. In this paper, we propose a data-driven approach for jointly solving two specific problems of deinterlacing and denoising that arise in interlaced video imaging with different exposures. First, we solve the deinterlacing problem using joint dictionary learning via sparse coding. Since partial information of detail in differently exposed rows is often available via interlacing, we make use of the information to reconstruct details of the extend dynamic range from the interlaced video input. Second, we jointly solve the denoising problem by tailoring sparse coding to better handle additive noise in low-/high-exposure rows, and also adopt multiscale homography flow to temporal sequences for denoising. We anticipate that the proposed method will allow for concurrent capture of higher dynamic range video frames without suffering from ghosting artifacts. We demonstrate the advantages of our interlaced video imaging compared with state-of-the-art high-dynamic-range video methods.
|
|
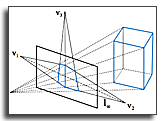 |
Urban Image Stitching using Planar Perspective Guidance
Joo Ho Lee, Seung-Hwan Baek, Min H. Kim
British Machine Vision Conference (BMVC 2017)
Sep. 04-07, 2017
|
[PDF][Supp.][BibTeX]
[Site] |
| |
Image stitching methods with spatially-varying homographies have been proposed to overcome partial misalignments caused by global perspective projection; however, local warp operators often fracture the coherence of linear structures, resulting in an inconsistent perspective. In this paper, we propose an image stitching method that warps a source image to a target image by local projective warps using planar perspective guidance. We first detect line structures that converge into three vanishing points, yielding line-cluster probability functions for each vanishing point. Then we estimate local homographies that account for planar perspective guidance from the joint probability of planar guidance, in addition to spatial coherence. This allows us to enhance linear perspective structures while warping multiple urban images with grid-like structures. Our results validate the effectiveness of our method over state-of-the-art projective warp methods in terms of planar perspective.
|
|
 |
Image Completion with Intrinsic Reflectance Guidance
Soomin Kim, Taeyoung Kim, Min H. Kim, Sung-Eui Yoon
British Machine Vision Conference (BMVC 2017)
Sep. 04-07, 2017
|
[PDF][Supp.][BibTeX]
[Site] |
| |
Patch-based image completion methods often fail in searching patch correspondences of similar materials due to shading caused by scene illumination, resulting in inappropriate image completion with dissimilar materials. We therefore present a novel image completion method that additionally accounts for intrinsic reflectance of scene objects, when searching patch correspondences. Our method examines both intrinsic reflectances and color image structures to avoid false correspondences of different materials so that our method can search and vote illumination-invariant patches robustly, allowing for image completion mainly with homogeneous materials. Our results validate that our reflectance-guided inpainting can produce more natural and consistent images than state-of-the-art inpainting methods even under various illumination conditions.
|
|
 |
Integrated Calibration of Multiview Phase-Measuring Profilometry
Yeong Beum Lee, Min H. Kim
Elsevier Optics and Lasers in Engineering (OLIE)
98C, Nov., 2017, pp. 118-122
|
[PDF][BibTeX][Site] |
| |
Phase-measuring profilometry (PMP) measures per-pixel height information of a surface with high accuracy. Height information captured by a camera in PMP relies on its screen coordinates. Therefore, a PMP measurement from a view cannot be integrated directly to other measurements from different views due to the intrinsic difference of the screen coordinates. In order to integrate multiple PMP scans, an auxiliary calibration of each camera's intrinsic and extrinsic properties is required, in addition to principal PMP calibration. This is cumbersome and often requires physical constraints in the system setup, and multiview PMP is consequently rarely practiced. In this work, we present a novel multiview PMP method that yields three-dimensional global coordinates directly so that three-dimensional measurements can be integrated easily. Our PMP calibration parameterizes intrinsic and extrinsic properties of the configuration of both a camera and a projector simultaneously. It also does not require any geometric constraints on the setup. In addition, we propose a novel calibration target that can remain static without requiring any mechanical operation while conducting multiview calibrations, whereas existing calibration methods require manually changing the target's position and orientation. Our results validate the accuracy of measurements and demonstrate the advantages on our multiview PMP.
|
|
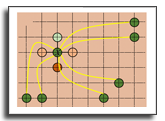 |
Dehazing using Non-Local Regularization with Iso-Depth Neighbor-Fields
Incheol Kim, Min H. Kim
Proc. Int. Joint Conf. Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017) - Volume 4: VISAPP
Feb. 27 - Mar. 1, 2017 (full paper, oral presentation)
|
[PDF][Supp.][PPT][BibTeX]
[Codes] |
| |
Removing haze from a single image is a severely ill-posed problem due to the lack of the scene information. General dehazing algorithms estimate airlight initially using natural image statistics and then propagate the incompletely estimated airlight to build a dense transmission map, yielding a haze-free image. Propagating haze is different from other regularization problems, as haze is strongly correlated with depth according to the physics of light transport in participating media. However, since there is no depth information available in single-image dehazing, traditional regularization methods with a common grid random field often suffer from haze isolation artifacts caused by abrupt changes in scene depths. In this paper, to overcome the haze isolation problem, we propose a non-local regularization method by combining Markov random fields (MRFs) with nearest-neighbor fields (NNFs), based on our insightful observation that the NNFs searched in a hazy image associate patches at the similar depth, as local haze in the atmosphere is proportional to its depth. We validate that the proposed method can regularize haze effectively to restore a variety of natural landscape images, as demonstrated in the results. This proposed regularization method can be used separately with any other dehazing algorithms to enhance haze regularization.
|
|
 |
Simultaneous Acquisition of Microscale Reflectance and Normals
Giljoo Nam, Joo Ho Lee, Hongzhi Wu, Diego Gutierrez, Min H. Kim
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2016
35(6), Dec. 05-08, 2016, pp. 185:1-11
|
[PDF][Supp.#1][PPT]
[Supp.#2][video][BibTeX] |
| |
Acquiring microscale reflectance and normals is useful for digital documentation and identification of real-world materials. However, its simultaneous acquisition has rarely been explored due to the difficulties of combining both sources of information at such small scale. In this paper, we capture both spatially-varying material appearance (diffuse, specular and roughness) and normals simultaneously at the microscale resolution. We design and build a microscopic light dome with 374 LED lights over the hemisphere, specifically tailored to the characteristics of microscopic imaging. This allows us to achieve the highest resolution for such combined information among current state-of-the-art acquisition systems. We thoroughly test and characterize our system, and provide microscopic appearance measurements of a wide range of common materials, as well as renderings of novel views to validate the applicability of our captured data. Additional applications such as bi-scale material editing from real-world samples are also demonstrated.
|
|
 |
Birefractive Stereo Imaging for Single-Shot Depth Acquisition
Seung-Hwan Baek, Diego Gutierrez, Min H. Kim
ACM Transactions on Graphics, presented at SIGGRAPH Asia 2016
35(6), Dec. 05-08, 2016, pp. 194:1-11
|
[PDF][Supp.#1][PPT]
[Supp.#2][BibTeX] |
| |
We propose a novel birefractive depth acquisition method, which allows for single-shot depth imaging by just placing a birefringent material in front of the lens. While most transmissive materials present a single refractive index per wavelength, birefringent crystals like calcite posses two, resulting in a double refraction effect. We develop an imaging model that leverages this phenomenon and the information contained in the ordinary and the extraordinary refracted rays, providing an effective formulation of the geometric relationship between scene depth and double refraction. To handle the inherent ambiguity of having two sources of information overlapped in a single image, we define and combine two different cost volume functions. We additionally present a novel calibration technique for birefringence, carefully analyze and validate our model, and demonstrate the usefulness of our approach with several image-editing applications.
|
|
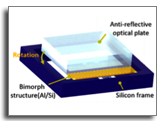 |
Electrothermal MEMS parallel plate rotation for single-imager stereoscopic endoscopes
Kyung-Won Jang, Sung-Pyo Yang, Seung-Hwan Baek, Min-Suk Lee, Hyeon-Cheol Park, Yeong-Hyeon Seo, Min H. Kim, Ki-Hun Jeong
OSA Optics Express (OE)
24 (9), May 2, 2016, pp. 9667-9672
|
[PDF][BibTeX][Site] |
| |
This work reports electrothermal MEMS parallel plate-rotation (PPR) for a single-imager based stereoscopic endoscope. A thin optical plate was directly connected to an electrothermal MEMS microactuator with bimorph structures of thin silicon and aluminum layers. The fabricated MEMS PPR device precisely rotates an transparent optical plate up to 37° prior to an endoscopic camera and creates the binocular disparities, comparable to those from binocular cameras with a baseline distance over 100 μm. The anaglyph 3D images and disparity maps were successfully achieved by extracting the local binocular disparities from two optical images captured at the relative positions. The physical volume of MEMS PPR is well fit in 3.4 mm x 3.3 mm x 1 mm. This method provides a new direction for compact stereoscopic 3D endoscopic imaging systems.
|
|
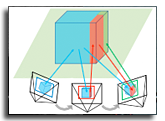 |
Multiview Image Completion with Space Structure Propagation
Seung-Hwan Baek, Inchang Choi, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2016)
Las Vegas, USA, June 26, 2016, pp. 488-496 |
[PDF][Supp.][BibTeX][Site] |
| |
We present a multiview image completion method that provides geometric consistency among different views by propagating space structures. Since a user specifies the region to be completed in one of multiview photographs casually taken in a scene, the proposed method enables us to complete the set of photographs with geometric consistency by creating or removing structures on the specified region. The proposed method incorporates photographs to estimate dense depth maps. We initially complete color as well as depth from a view, and then facilitate two stages of structure propagation and structure-guided completion. Structure propagation optimizes space topology in the scene across photographs, while structure-guide completion enhances, and completes local image structure of both depth and color in multiple photographs with structural coherence by searching nearest neighbor fields in relevant views. We demonstrate the effectiveness of the proposed method in completing multiview images.
|
|
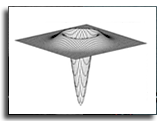 |
Laplacian Patch-Based Image Synthesis
Joo Ho Lee, Inchang Choi, Min H. Kim
Proc. IEEE Computer Vision and Pattern Recognition (CVPR 2016)
Las Vegas, USA, June 26, 2016, pp. 2727-2735 |
[PDF][Supp.][BibTeX]
[Code][Site] |
| |
Patch-based image synthesis has been enriched with global optimization on the image pyramid. Successively, the gradient-based synthesis has improved structural coherence and details. However, the gradient operator is directional and inconsistent and requires computing multiple operators. It also introduces a significantly heavy computational burden to solve the Poisson equation that often accompanies artifacts in non-integrable gradient fields. In this paper, we propose a patch-based synthesis using a Laplacian pyramid to improve searching correspondence with enhanced awareness of edge structures. Contrary to the gradient operators, the Laplacian pyramid has the advantage of being isotropic in detecting changes to provide more consistent performance in decomposing the base structure and the detailed localization. Furthermore, it does not require heavy computation as it employs approximation by the differences of Gaussians. We examine the potentials of the Laplacian pyramid for enhanced edge-aware correspondence search. We demonstrate the effectiveness of the Laplacian-based approach over the state-of-the-art patch-based image synthesis methods.
|
|
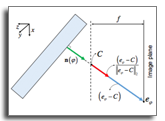 |
Stereo Fusion: Combining Refractive and Binocular Disparity
Seung-Hwan Baek, Min H. Kim
Elsevier Computer Vision and Image Understanding (CVIU)
146, May 01, 2016, pp. 52-66 |
[PDF][BibTeX][Slides][Site] |
| |
The performance of depth reconstruction in binocular stereo relies on how adequate the predefined baseline for a target scene is. Wide-baseline stereo is capable of discriminating depth better than the narrow-baseline stereo, but it often suffers from spatial artifacts. Narrow-baseline stereo can provide a more elaborate depth map with fewer artifacts, while its depth resolution tends to be biased or coarse due to the short disparity. In this paper, we propose a novel optical design of heterogeneous stereo fusion on a binocular imaging system with a refractive medium, where the binocular stereo part operates as wide-baseline stereo, and the refractive stereo module works as narrow-baseline stereo. We then introduce a stereo fusion workflow that combines the refractive and binocular stereo algorithms to estimate fine depth information through this fusion design. In addition, we propose an efficient calibration method for refractive stereo. The quantitative and qualitative results validate the performance of our stereo fusion system in measuring depth in comparison with homogeneous stereo approaches.
|
|
 |
Multisampling Compressive Video Spectroscopy
Daniel S. Jeon, Inchang Choi, Min H. Kim
Computer Graphics Forum (CGF), presented at EUROGRAPHICS 2016
35(2), May 12, 2016, pp. 467-477 |
[PDF][Video][PPT][BibTeX] |
| |
The coded aperture snapshot spectral imaging (CASSI) architecture has been employed widely for capturing hyperspectral video. Despite allowing concurrent capture of hyperspectral video, spatial modulation in CASSI sacrifices image resolution significantly while reconstructing spectral projection via sparse sampling. Several multiview alternatives have been proposed to handle this low spatial resolution problem and improve measurement accuracy, for instance, by adding a translation stage for the coded aperture or changing the static coded aperture with a digital micromirror device for dynamic modulation. State- of-the-art solutions enhance spatial resolution significantly but are incapable of capturing video using CASSI. In this paper, we present a novel compressive coded aperture imaging design that increases spatial resolution while capturing 4D hyperspectral video of dynamic scenes. We revise the traditional CASSI design to allow for multiple sampling of the randomness of spatial modulation in a single frame. We demonstrate that our compressive video spectroscopy approach yields enhanced spatial resolution and consistent measurements, compared with the traditional CASSI design.
|
|
 |
Electrothermal MEMS Parallel Plate Rotation for Real Time Stereoscopic Endoscopic Imaging
Kyung-Won Jang, Sung-Pyo Yang, Seung-Hwan Baek, Min H. Kim, Ki-Hun Jeong
Proc. IEEE International Conference on Micro Electro Mechanical Systems (MEMS 2016)
Shanghai, China, Jan. 24, 2016, 4 pages.
|
[Site][BibTeX] |
 |
Ultrathin Camera Inspired by Visual System Of Xenos Peckii
Dongmin Keum, Daniel S. Jeon, Charles S. H. Hwang, Elke K. Buschbeck,
Min H. Kim, Ki-Hun Jeong
Proc. IEEE International Conference on Micro Electro Mechanical Systems (MEMS 2016)
Shanghai, China, Jan. 24, 2016, 4 pages.
|
[Site][BibTeX] |
 |
Foundations and Applications of 3D Imaging
Min H. Kim
In Theory and Applications of Smart Cameras
edited by Chong-Min Kyung
Chapter I.4, pp. 63-84, Springer
|
[Publisher][BibTeX] |
| |
Two-dimensional imaging through digital photography has been a main application of mobile computing devices, such as smart phones, during the last decade. Expanding the dimensions of digital imaging, the recent advances in 3D imaging technology are about to be combined with such smart devices, resulting in broadened applications of 3D imaging. This chapter presents the foundations of 3D imaging, that is, the relationship between disparity and depth in a stereo camera system, and it surveys a general workflow to build a 3D model from sensor data. In addition, recent advanced 3D imaging applications are introduced: hyperspectral 3D imaging, multispectral photometric stereo and stereo fusion of refractive and binocular stereo.
|
 |
Measuring Color Defects in Flat Panel Displays
using HDR Imaging and Appearance Modeling
Giljoo Nam, Haebom Lee, Sungsoo Oh, Min H. Kim
IEEE Transactions on Instrumentation and Measurement (TIM)
Oct. 19, 2015, 65(2), pp.297--304
|
[DL][PDF][BibTeX] |
| |
Measuring and quantifying color defects in flat panel displays (FPDs) are critical in the FPD industry and related busi- ness. Color defects are traditionally investigated by professional human assessors as color defects are subtle perceptual phenomena that are difficult to detect using a camera system. However, human-based inspection has hindered the quantitative analysis of such color defects. Thus, the industrial automation of color defect measurement in FPDs has been severely limited even by leading manufacturers accordingly. This paper presents a systematic framework for the measurement and numerical evaluation of color defects. Our framework exploits high-dynamic-range (HDR) imaging to robustly measure physically-meaningful quantities of subtle color defects. In addition to the application of advanced imaging technology, an image appearance model is employed to predict the human visual perception of color defects as human assessors do. This proposed automated framework can output quantitative analysis of the color defects. This work demonstrates the performance of the proposed workflow in investigating subtle color defects in FPDs with a high accuracy.
|
|
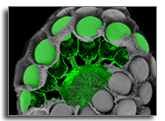 |
Artificial Compound Eye Inspired by Imaging Principle Of Xenos Peckii
Dongmin Keum, Daniel S. Jeon, Min H. Kim, Ki-Hun Jeong
Proc. IEEE International Conference on Solid-State Sensors, Actuators and Microsystems (TRANSDUCERS 2015)
Anchorage, Alaska, USA, Jun. 21, 2015, 4 pages.
|
[DL][BibTeX] |
 |
Single Camera based Miniaturized Stereoscopic System for 3D Endoscopic Imaging
Kyung-Won Jang, Sung-Pyo Yang, Seung-Hwan Baek, Min H. Kim, Ki-Hun Jeong
Proc. SPIE Nano-Bio Sensing Imaging and Spectroscopy (NBSIS 2015)
Jeju, Korea, Feb. 25, 2015.
|
[DL][BibTeX] |
 |
The Three-Dimensional Evolution of Hyperspectral Imaging
Min H. Kim
In Smart Sensors and Systems
edited by Youn-Long Lin, Chong-Min Kyung, Hiroto Yasuura, and Yongpan Liu
Chapter II.1, pp. 63-84, Springer
|
[Publisher][BibTeX] |
| |
Hyperspectral imaging has become more accessible nowadays as an image-based acquisition tool for physically-meaningful measurements. This technology is now evolving from classical 2D imaging to 3D imaging, allowing us to measure physically-meaningful reflectance on 3D solid objects. This chapter provides a brief overview on the foundations of hyperspectral imaging and introduces advanced applications of hyperspectral 3D imaging. This chapter first surveys the fundamentals of optics and calibration processes of hyperspectral imaging and then studies two typical designs of hyperspectral imaging. In addition to this introduction, this chapter briefly looks over the state-of-the-art applications of hyperspectral 3D imaging to measure hyperspectral intrinsic properties of surfaces on 3D solid objects.
|
|
 |
Lock N' LoL: Mitigating Smartphone Disturbance in Co-located Social Interactions
Minsam Ko, Chayanin Wong, Sunmin Son, Euigon Jung, Uichin Lee,
Seungwoo Choi, Sungho Jo, Min H. Kim
Proc. ACM CHI 2015 Extended Abstracts
April 2015, Work in Progress, pp. 1561--1566
|
[DL][PDF][BibTeX] |
| |
We aim to improve the quality of time spent in co-located social interactions by encouraging people to limit their smartphone usage together. We present a prototype called Lock n’ LoL, an app that allows co-located users to lock their smartphones and limit their usage by enforcing users to ask for explicit use permission. From our preliminary study, we designed two modes to deal with the dynamics of smartphone use during the co-located social interactions: (1) socializing mode (i.e., locking smartphones to limit usage together) and (2) temporary use mode (i.e., requesting/granting temporary smartphone use). We conducted a pilot study (n = 20) with our working prototype, and the results documented the helpfulness of Lock n' LoL when used in socializing.
|
|
 |
Stereo Fusion using a Refractive Medium on a Binocular Base
Seung-Hwan Baek, Min H. Kim
Proc. Asian Conference on Computer Vision (ACCV) 2014
Best Application Paper Award & Best Demo Award
Apr. 16, 2015, Springer LNCS Vol. 9004, Part II, pp. 503-518 (oral presentation)
|
[DL][PDF][BibTeX][PPT] |
| |
The performance of depth reconstruction in binocular stereo relies on how adequate the predefined baseline for a target scene is. Long-baseline stereo is capable of discriminating depth better than the short one, but it often suffers from spatial artifacts. Short-baseline stereo can provide a more elaborate depth map with less artifacts, while its depth resolution tends to be biased or coarse due to the short disparity. In this paper, we first propose a novel optical design of heterogeneous stereo fusion on a binocular imaging system with a refractive medium, where the binocular stereo part operates as long-baseline stereo; the refractive stereo module functions as short-baseline stereo. We then introduce a stereo fusion workflow that combines the refractive and binocular stereo algorithms to estimate fine depth information through this fusion design. The quantitative and qualitative results validate the performance of our stereo fusion system in measuring depth, compared with traditional homogeneous stereo approaches.
|
|
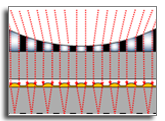 |
Design and microfabrication of
an artificial compound eye inspired by vision mechanism of Xenos peckii
Dongmin Keum, Inchang Choi, Min H. Kim, Ki-Hun Jeong
Proc. SPIE Photonics West 2015
San Francisco, California, USA, Feb. 7–8 2015, Vol. 9341, Article. 4.
|
[DL][BibTeX] |
 |
Multispectral Photometric Stereo for Acquiring High-Fidelity Surface Normals
Giljoo Nam, Min H. Kim
IEEE Computer Graphics and Applications (CG&A)
Sep. 09, 2014, 34(6), pp.57--68.
|
[DL][PDF][BibTeX] |
| |
An advanced imaging technique of multispectral imaging has become more accessible as a physically-meaningful image-based measurement tool, and photometric stereo has been commonly practiced for digitizing a 3D shape with simplicity for more than three decades. However, these two imaging techniques have rarely been combined as a 3D imaging application yet. Reconstructing the shape of a 3D object using photometric stereo is still challenging due to the optical phenomena such as indirect illumination, specular reflection, self shadow. In addition, removing interreflection in photometric stereo is a traditional chicken-and-egg problem as we need to account for interreflection without knowing geometry. In this paper, we present a novel multispectral photometric stereo method that allows us to remove interreflection on diffuse materials using multispectral reflectance information. Our proposed method can be easily integrated into an existing photometric stereo system by simply substituting the current camera with a multispectral camera, as our method does not rely on additional structured or colored lights. We demonstrate several benefits of our multispectral photometric stereo method such as removing interreflection and reconstructing the 3D shapes of objects to a high accuracy.
|
|
 |
Paper3D: Bringing Casual 3D Modeling to a Multi-Touch Interface
Patrick Paczkowski, Julie Dorsey, Holly Rushmeier, Min H. Kim
Proc. ACM User Interface Software & Technology Symposium (UIST) 2014
Oct. 5, 2014, pp. 23-32 (oral presentation).
|
[PDF][DL][Video][BibTeX] |
| |
A 3D modeling system that provides all-inclusive functionality is generally too demanding for a casual 3D modeler to learn. In recent years, there has been a shift towards developing more approachable systems, with easy-to-learn, intuitive interfaces. However, most modeling systems still employ mouse and keyboard interfaces, despite the ubiquity of tablet devices, and the benefits of multi-touch interfaces applied to 3D modeling. In this paper, we introduce an alternative 3D modeling paradigm for creating developable surfaces, inspired by traditional papercrafting, and implemented as a system designed from the start for a multi-touch tablet. We demonstrate the process of assembling complex 3D scenes from a collection of simpler models, in turn shaped through operations applied to sheets of virtual paper. The modeling and assembling operations mimic familiar, real-world operations performed on paper, allowing users to quickly learn our system with very little guidance. We outline key design decisions made throughout the development process, based on feedback obtained through collaboration with target users. Finally, we include a range of models created in our system.
|
|
 |
Locally Adaptive Products for Genuine Spherical Harmonic Lighting
Joo Ho Lee, Min H. Kim
Proc. International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision (WSCG) 2014
Jun. 2, 2014, pp. 27-36 (oral presentation)
|
[DL][PDF][BibTeX] |
| |
Precomputed radiance transfer techniques have been broadly used for supporting complex illumination effects on diffuse and glossy objects. Although working with the wavelet domain is efficient in handling all-frequency illumination, the spherical harmonics domain is more convenient for interactively changing lights and views on the fly due to the rotational invariant nature of the spherical harmonic domain. For interactive lighting, however, the number of coefficients must be limited and the high orders of coefficients have to be eliminated. Therefore spherical harmonic lighting has been preferred and practiced only for interactive soft-diffuse lighting. In this paper, we propose a simple but practical filtering solution using locally adaptive products of high-order harmonic coefficients within the genuine spherical harmonic lighting framework. Our approach works out on the fly in two-fold. We first conduct multi-level filtering on vertices in order to determine regions of interests, where the high orders of harmonics are necessary for high frequency lighting. The initially determined regions of interests are then refined through filling in the incomplete regions by traveling the neighboring vertices. Even not relying on graphics hardware, the proposed method allows to compute high order products of spherical harmonic lighting for both diffuse and specular lighting.
|
|
 |
Building a Two-Way Hyperspectral Imaging System with Liquid Crystal Tunable Filters
Haebom Lee, Min H. Kim
Proc. Int. Conf. Image and Signal Processing (ICISP) 2014,
LNCS Vol. 8509,
Jul. 2, 2014, pp. 26-34 (oral presentation)
|
[DL][PDF][BibTeX] |
| |
Liquid crystal tunable filters can provide rapid and vibrationless section of any wavelength in transmitting spectrum so that they have been broadly used in building multispectral or hyperspectral imaging systems. However, the spectral range of the filters is limited to a certain range, such as visible or near-infrared spectrum. In general hyperspectral imaging applications, we are therefore forced to choose a certain range of target spectrum, either visible or near-infrared for instance. Owing to the nature of polarizing optical elements, imaging systems combined with multiple tunable filters have been rarely practiced. In this paper, we therefore present our experience of building a two-way hyperspectral imaging system with liquid crystal tunable filters. The system allows us to capture hyperspectral radiance continuously from visible to near-infrared spectrum (400-1100 nm at 7 nm intervals), which is 2.3 times wider and 34 times more channels compared to a common RGB camera. We report how we handle the multiple polarizing elements to extend the spectral range of the imager with the multiple tunable filters and propose an affine-based method to register the hyperspectral image channels of each wavelength.
|
|
 |
Hyper3D: 3D Graphics Software for Examining Cultural Artifacts
Min H. Kim, Holly Rushmeier, John ffrench, Irma Passeri, David Tidmarsh
ACM Journal on Computing and Cultural Heritage (JOCCH)
7(3), Aug. 01, 2014, pp. 1:1-19
|
[DL][PDF][BibTeX][Code] |
| |
Art conservators now have access to a wide variety of digital imaging techniques to assist in examining and documenting physical works of art. Commonly used techniques include hyperspectral imaging, 3D scanning and medical CT imaging. However, viewing most of this digital image data frequently requires both specialized software, which is often associated with a particular type of acquisition device, and professional knowledge of and experience with each type of data. In addition, many of these software packages are focused on particular applications (such as medicine or remote sensing) and do not permit users to access and fully exploit all the information contained in the data. In this paper, we address two practical barriers to using high-tech digital data in art conservation. First, users must deal with a wide variety of interfaces specialized for applications besides conservation. We provide an open-source software tool with a single intuitive interface consistent with conservators’ needs that handles various types of 2D and 3D image data and preserves user-generated metadata and annotations. Second, previous software has largely allowed visualizing a single type or only a few types of data. The software we present is designed and structured to accommodate multiple types of digital imaging data, including as yet unspecified or unimplemented formats, in an integrated environment. This allows conservators to access different forms of information and to view a variety of image types simultaneously.
|
|
 |
Digital Cameras: Definitions and Principles
Min H. Kim, Nicolas Hautiere, Celine Loscos
In 3D Video: From Capture to Diffusion
edited by Laurent Lucas, Celine Loscos and Yannick Remion
Chapter 2, pp. 23-42, Wiley-ISTE, London
|
[Publisher][BibTeX] |
| |
Digital cameras are a common feature of most mobile phones. In this chapter, we will outline the basics of digital cameras to help users understand the differences between image features formed by sensors and optics in order to control their governing parameters more precisely. We will examine a digital camera that captures not only still images but also video, given that most modern cameras are capable of capturing both types of image data. This chapter provides a general overview of current camera components required in three-dimensional (3D) processing and labeling, which will be examined in the remainder of this book. We will study each stage of light transport via the camera’s optics, before light is captured as an image by the sensor and stored in a given format. Section 2.2 introduces the fundamentals of light transport as well as notations for wavelength and color spaces, commonly used in imaging. Section 2.3 examines how cameras have been adapted to capture and transform into digital image. This section also describes the details of different components in a camera and their influence on the final image. In particular, we will provide a brief overview of different optical components and sensors, examining their advantages and limitations. This section also explains how these limitations can be corrected by applying post-processing algorithms to the acquired images. Section 2.4 investigates the link between camera models and the human visual system in terms of perception, optics and color fidelity. Section 2.5 briefly explores two current camera techniques; high dynamic range (HDR) and hyperspectral imaging.
|
|
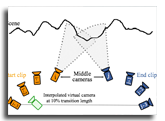 |
Preference and Artifact Analysis for Video Transitions of Places
James Tompkin, Min H. Kim, Kwang In Kim, Jan Kautz, Christian Theobalt
ACM Transactions on Applied Perception (TAP), presented at SAP 2013
10(3), Aug. 01, 2013, pp. 13:1-19
|
[DL][PDF][Video][BibTeX] |
| |
Emerging interfaces for video collections of places attempt to link similar content with seamless transitions. However, the automatic computer vision techniques that enable these transitions have many failure cases which lead to artifacts in the final rendered transition. Under these conditions, which transitions are preferred by participants and which artifacts are most objectionable? We perform an experiment with participants comparing seven transition types, from movie cuts and dissolves to image-based warps and virtual camera transitions, across five scenes in a city. This document describes how we condition this experiment on slight and considerable view change cases, and how we analyze the feedback from participants to find their preference for transition types and artifacts. We discover that transition preference varies with view change, that automatic rendered transitions are significantly preferred even with some artifacts, and that dissolve transitions are comparable to less- sophisticated rendered transitions. This leads to insights into what visual features are important to maintain in a rendered transition, and to an artifact ordering within our transitions.
|
|
 |
3D Graphics Techniques for Capturing and Inspecting Hyperspectral Appearance
Min H. Kim
IEEE International Symposium on Ubiquitous Virtual Reality (ISUVR) 2013
Jul. 10, 2013, pp. 15-18
|
[DL][PDF][BibTeX] |
| |
Feature films and computer games exhibit stunning photorealistic computer imagery in motion. The challenges in computer graphics realism lie in acquiring physically accurate material appearance in a high spectral resolution and representing the appearance with perceptual faithfulness. While many approaches for true spectral rendering have been tried in computer graphics, they have not been extensively explored due to the lack of reliable 3D spectral data. Recently, a hyperspectral 3D acquisition system and viewing software have been introduced to the graphics community. In this paper, we review the latest acquisition and visualization techniques for hyperspectral imaging in graphics. We give an overview of the 3D imaging system for capturing hyperspectral appearance on 3D objects and the visualization software package to exploit such high-tech digital data.
|
|
 |
Developing Open-Source Software for Art Conservators
Min H. Kim, Holly Rushmeier, John ffrench, Irma Passeri
International Symposium on Virtual Reality, Archaeology and Cultural Heritage
(VAST 2012)
Best Paper Award
Nov. 19, 2012, pp. 97-104 |
[DL][PDF][BibTeX] |
| |
Art conservators now have access to a wide variety of digital imaging techniques to assist in examining and documenting physical works of art. Commonly used techniques include hyperspectral imaging, 3D scanning and medical CT imaging. However, most of the digital image data requires specialized software to view. The software is often associated with a particular type of acquisition device, and professional knowledge and experience is needed for each type of data. In addition, these software packages are often focused on particular applications (such as medicine or remote sensing) and are not designed to allow the free exploitation of these expensively acquired digital data. In this paper, we address two practical barriers in using the high-tech digital data in art conservation. First, there is the barrier of dealing with a wide variety of interfaces specialized for applications outside of art conservation. We provide an open-source software tool with a single intuitive user interface that can handle various types of 2/3D image data consistent with the needs of art conservation. Second, there is the barrier that previous software has been focused on a single data type. The software presented here is designed and structured to integrate various types of digital imaging data, including as yet unspecified data types, in an integrated environment. This provides conservators the free navigation of various imaging information and allows them to integrate the different types of imaging observations.
|
|
 |
3D Imaging Spectroscopy for Measuring Hyperspectral Patterns on Solid Objects
Min H. Kim, Todd Alan Harvey, David S. Kittle, Holly Rushmeier, Julie Dorsey,
Richard O. Prum, David J. Brady
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2012
31(4), Aug. 05, 2012, pp. 38:1-11 |
[DL][PDF][Video][BibTeX] |
| |
Sophisticated methods for true spectral rendering have been de- veloped in computer graphics to produce highly accurate images. In addition to traditional applications in visualizing appearance, such methods have potential applications in many areas of scientific study. In particular, we are motivated by the application of studying avian vision and appearance. An obstacle to using graphics in this application is the lack of reliable input data. We introduce an end-to- end measurement system for capturing spectral data on 3D objects. We present the modification of a recently developed hyperspectral imager to make it suitable for acquiring such data in a wide spec- tral range at high spectral and spatial resolution. We capture four megapixel images, with data at each pixel from the near-ultraviolet (359 nm) to near-infrared (1,003 nm) at 12 nm spectral resolution. We fully characterize the imaging system, and document its accuracy. This imager is integrated into a 3D scanning system to enable the measurement of the diffuse spectral reflectance and fluorescence of specimens. We demonstrate the use of this measurement system in the study of the interplay between the visual capabilities and ap- pearance of birds. We show further the use of the system in gaining insight into artifacts from geology and cultural heritage.
|
|
 |
Insitu: Sketching Architectural Designs in Context
Patrick Paczkowski, Min H. Kim, Yann Morvan, Julie Dorsey, Holly Rushmeier,
Carol O'Sullivan
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2011
30(6), Dec. 12, 2011, pp. 182:1-10 |
[DL][PDF][Video][BibTeX]
|
| |
Architecture is design in spatial context. The only current methods for representing context involve designing in a heavyweight computer-aided design system, using a full model of existing buildings and landscape, or sketching on a panoramic photo. The former is too cumbersome; the latter is too restrictive in viewpoint and in the handling of occlusions and topography. We introduce a novel approach to presenting context such that it is an integral
component in a lightweight conceptual design system. We represent sites through a fusion of data available from different sources. We derive a site model from geographic elevation data, on-site point-to-point distance measurements, and images of the site. To acquire and process the data, we use publicly available data sources, multi-dimensional scaling techniques and refinements of recent bundle adjustment techniques. We offer a suite
of interactive tools to acquire, process, and combine the data into a lightweight stroke and image-billboard representation.
We create multiple and linked pop-ups derived from images, forming a lightweight representation of a three-dimensional environment.
We implemented our techniques in a stroke-based conceptual design system we call Insitu.
We developed our work through continuous interaction with professional designers.
We present designs created with our new techniques integrated in a conceptual design system.
|
|
 |
Radiometric Characterization of Spectral
Imaging for Textual Pigment Identification
Min H. Kim, Holly Rushmeier
International Symposium on Virtual Reality, Archaeology and Cultural Heritage
(VAST 2011)
Oct. 18, 2011, pp. 57-64 |
[DL][PDF][BibTeX] |
| |
Digital imaging of cultural heritage artifacts has become a standard practice. Typically, standard commercial cameras, often commodity rather than scientific grade cameras, are used for this purpose. Commercial cameras are optimized for plausible visual reproduction of a physical scene with respect to trichromatic human vision. However, visual reproduction is just one application of digital images in heritage. In this paper, we discuss the selection and characterization of an alternative imaging system that can be used for the physical analysis of artifacts as well as visually reproducing their appearance. The hardware and method we describe offers a middle ground between the low cost and ease of commodity cameras and the high cost and complexity of hyperspectral imaging systems. We describe the selection of a system, a protocol for characterizing the system and provide a case study using the system in the physical analysis of a medieval manuscript. |
|
 |
Design and Fabrication of a UV-Visible Coded Aperture Spectral Imager (CASI)
David Kittle, Daniel L. Marks, Min H. Kim, Holly Rushmeier, David J. Brady
Frontiers in Optics 2011, Optical Society of America (OSA)
Oct. 16, 2011, paper FTuZ3 |
[DL][PDF][BibTeX] |
| |
CASI is a snapshot capable UV-visible spectral imager for measuring bird plumage. Near apochromatic UV-visible optics were designed and built with an MTF for a 4Mpx detector. Wide-spectral bandwidth data from CASI is then presented. |
 |
Edge-Aware Color Appearance
Min H. Kim, Tobias Ritschel, Jan Kautz
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2011
30(2), Apr. 01, 2011, pp. 13:1-9 |
[DL][PDF][Data][BibTeX] |
| |
Color perception is recognized to vary with surrounding spatial structure, but the impact of edge smoothness on color has not been studied in color appearance modeling. In this work, we study the appearance of color under different degrees of edge smoothness. A psychophysical experiment was conducted to quantify the change in perceived lightness, colorfulness and hue with respect to edge smoothness. We confirm that color appearance, in particular lightness, changes noticeably with increased smoothness. Based on our experimental data, we have developed a computational model that predicts this appearance change. The model can be integrated into existing color appearance models. We demonstrate the applicability of our model on a number of examples. |
 |
High-Fidelity Colour Reproduction for High-Dynamic-Range Imaging
Min H. Kim
PhD Thesis in Computer Science
2010, University College London, London, UK |
[DL][PDF][BibTeX] |
| |
The aim of this thesis is to develop a colour reproduction system for high-dynamic-range (HDR) imaging. Classical colour reproduction systems fail to reproduce HDR images because current characterisation methods and colour appearance models fail to cover the dynamic range of luminance present in HDR images. HDR tone-mapping algorithms have been developed to reproduce HDR images on low-dynamic-range media such as LCD displays. However, most of these models have only considered luminance compression from a photographic point of view and have not explicitly taken into account colour appearance. Motivated by the idea to bridge the gap between cross-media colour reproduction and HDR imaging, this thesis investigates the fundamentals and the infrastructure of cross-media colour reproduction. It restructures cross-media colour reproduction with respect to HDR imaging, and develops a novel cross-media colour reproduction system for HDR imaging. First, our HDR characterisation method enables us to measure HDR radiance values to a high accuracy that rivals spectroradiometers. Second, our colour appearance model enables us to predict human colour perception under high luminance levels. We first built a high-luminance display in order to establish a controllable high-luminance viewing environment. We conducted a psychophysical experiment on this display device to measure perceptual colour attributes. A novel numerical model for colour appearance was derived from our experimental data, which covers the full working range of the human visual system. Our appearance model predicts colour and luminance attributes under high luminance levels. In particular, our model predicts perceived lightness and colourfulness to a significantly higher accuracy than other appearance models. Finally, a complete colour reproduction pipeline is proposed using our novel HDR characterisation and colour appearance models. Results indicate that our reproduction system outperforms other reproduction methods with statistical significance. Our colour reproduction system provides high-fidelity colour reproduction for HDR imaging, and successfully bridges the gap between cross-media colour reproduction and HDR imaging. |
|
 |
Perceptual Influence of Approximate Visibility in Indirect Illumination
Insu Yu, Andrew Cox, Min H. Kim, Tobias Ritschel, Thorsten Grosch,
Carsten Dachsbacher, Jan Kautz
ACM Transactions on Applied Perception (TAP), presented at APGV 2009
6(4), Sep. 01, 2009, pp. 24:1-14 |
[DL][PDF][BibTeX]
|
| |
In this paper we evaluate the use of approximate visibility for efficient
global illumination. Traditionally, accurate visibility is used in
light transport. However, the indirect illumination we perceive on a
daily basis is rarely of high frequency nature, as the most significant
aspect of light transport in real-world scenes is diffuse, and thus
displays a smooth gradation. This raises the question of whether
accurate visibility is perceptually necessary in this case. To answer
this question, we conduct a psychophysical study on the perceptual
influence of approximate visibility on indirect illumination. This
study reveals that accurate visibility is not required and that certain
approximations may be introduced. |
 |
Modeling Human Color Perception under Extended Luminance Levels
Min H. Kim, Tim Weyrich, Jan Kautz
ACM Transactions on Graphics (TOG), presented at SIGGRAPH 2009
28(3), Jul. 27, 2009, pp. 27:1-9 |
[DL][PDF][Examples]
[Data][BibTeX][Code] |
| |
Display technology is advancing quickly with peak luminance increasing significantly, enabling high-dynamic-range displays. However, perceptual color appearance under extended luminance levels has not been studied, mainly due to the unavailability of psychophysical data. Therefore, we conduct a psychophysical study in order to acquire appearance data for many different luminance levels (up to 16,860 cd/m2) covering most of the dynamic range of the human visual system. These experimental data allow us to quantify human color perception under extended luminance levels, yielding a generalized color appearance model. Our proposed appearance model is efficient, accurate and invertible. It can be used to adapt the tone and color of images to different dynamic ranges for cross-media reproduction while maintaining appearance that is close to human perception. |
|
 |
Consistent Scene Illumination using a Chromatic Flash
Min H. Kim,
Jan Kautz
Eurographics Workshop on Computational Aesthetics (CAe) 2009
May 28, 2009, pp. 83-89 |
[DL][PDF][Video][BibTeX] |
| |
Flash photography is commonly used in low-light conditions to prevent noise and blurring artifacts. However, flash photography commonly leads to a mismatch between scene illumination and flash illumination, due to the bluish light that flashes emit. Not only does this change the atmosphere of the original scene illumination, it also makes it difficult to perform white balancing because of the illumination differences. Professional photographers sometimes apply colored gel filters to the flashes in order to match the color temperature. While effective, this is impractical for the casual photographer. We propose a simple but powerful method to automatically match the correlated color temperature of the auxiliary flash light with that of scene illuminations allowing for well-lit photographs while maintaining the atmosphere of the scene. Our technique consists of two main components. We first estimate the correlated color temperature of the scene, e.g., during image preview. We then adjust the color temperature of the flash to the scene’s correlated color temperature, which we achieve by placing a small trichromatic LCD in front of the flash. We demonstrate the effectiveness of this approach with a variety of examples. |
|
 |
Imperfect Shadow Maps for Efficient Computation of Indirect Illumination
Tobias Ritschel, Thorsten Grosch, Min H. Kim, Hans-Peter Seidel,
Carsten Dachsbacher,
Jan Kautz
ACM Transactions on Graphics (TOG), presented at SIGGRAPH Asia 2008
27(5), Dec. 10, 2008, pp. 129:1-8 |
[DL][PDF][Video][BibTeX] |
| |
We present a method for interactive computation of indirect illumination in large and fully dynamic scenes based on approximate visibility queries. While the high-frequency nature of direct lighting requires accurate visibility, indirect illumination mostly consists of smooth gradations, which tend to mask errors due to incorrect visibility. We exploit this by approximating visibility for indirect illumination with imperfect shadow maps-low-resolution shadow maps rendered from a crude point-based representation of the scene. These are used in conjunction with a global illumination algorithm based on virtual point lights enabling indirect illumination of dynamic scenes at real-time frame rates. We demonstrate that imperfect shadow maps are a valid approximation to visibility, which makes the simulation of global illumination an order of magnitude faster than using accurate visibility. |
|
 |
Characterization for High Dynamic Range Imaging
Min H. Kim, Jan Kautz
Computer Graphics Forum (CGF), presented at EUROGRAPHICS 2008
27(2), Apr. 24, 2008, pp. 691-697 |
[DL][PDF][BibTeX] |
| |
In this paper we present a new practical camera characterization technique to improve color accuracy in high dynamic range (HDR) imaging. Camera characterization refers to the process of mapping device-dependent signals, such as digital camera RAW images, into a well-defined color space. This is a well-understood process for low dynamic range (LDR) imaging and is part of most digital cameras - usually mapping from the raw camera signal to the sRGB or Adobe RGB color space. This paper presents an efficient and accurate characterization method for high dynamic range imaging that extends previous methods originally designed for LDR imaging. We demonstrate that our characterization method is very accurate even in unknown illumination conditions, effectively turning a digital camera into a measurement device that measures physically accurate radiance values - both in terms of luminance and color - rivaling more expensive measurement instruments. |
|
 |
Consistent Tone Reproduction
Min H. Kim, Jan Kautz
IASTED Conference on Computer Graphics and Imaging (CGIM) 2008
Feb. 13, 2008, pp.152-159 |
[DL][PDF][BibTeX][Software] |
| |
In order to display images of high dynamic range (HDR), tone reproduction operators are usually applied that reduce the dynamic range to that of the display device. Generally, parameters need to be adjusted for each new image to achieve good results. Consistent tone reproduction across different images is therefore difficult to achieve, which is especially true for global operators and to some lesser extent also for local operators. We propose an efficient global tone reproduction method that achieves robust results across a large variety of HDR images without the need to adjust parameters. Consistency and efficiency make our method highly suitable for automated dynamic range compression, which for instance is necessary when a large number of HDR images need to be converted. |
 |
Rendering High Dynamic Range Images
Min H. Kim, Lindsay W. MacDonald
EVA 2006 London Conference, EVA Conferences International (EVA) 2006
Jul. 25, 2006, pp. 22.1-11 |
[PDF][BibTeX] |
| |
A high dynamic range (HDR) imaging system, has been developed to overcome the limitations of dynamic range of a typical digital image reproduction system. The first stage is an HDR image-assembling algorithm, which constructs an HDR image from a sequence of multiple image exposures of a scene. The second stage utilises a new file format to store the HDR image in three primaries of 16-bits each. The third stage, described in this paper, uses a new tone-mapping algorithm to display HDR images on typical displays, optimised for sRGB devices. Six HDR tone-mapping techniques were evaluated by observers, and the new technique showed the best performance in all four category judgements: overall, tone, colour, and sharpness. |
|
|
|
|
© Visual Computing Laboratory, School of Computing, KAIST.
All rights reserved.
|
 |
|

